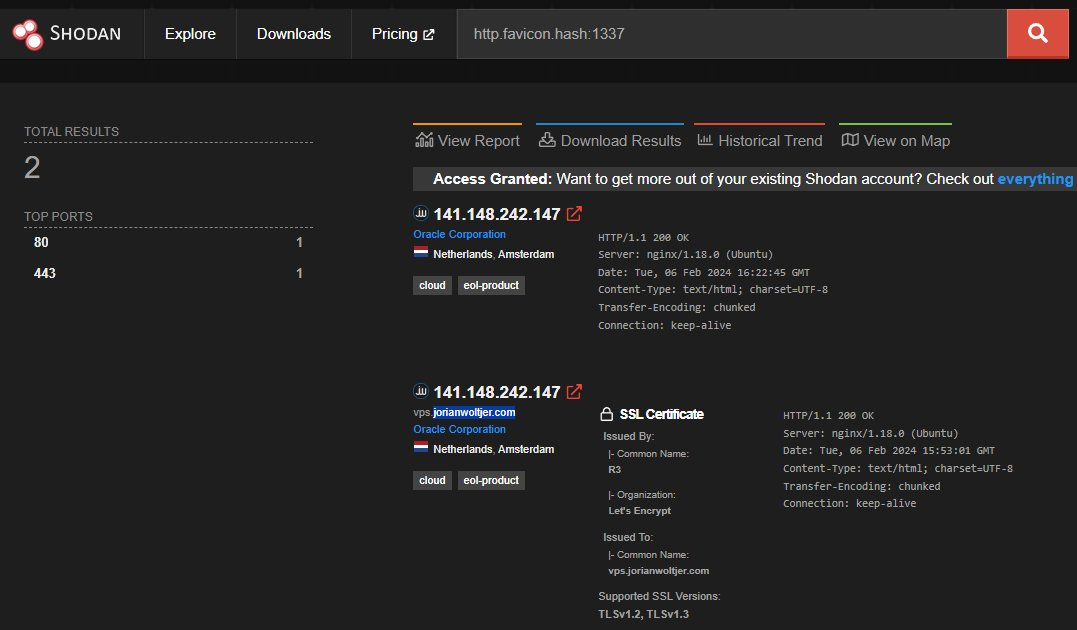
While playing around with Shodan's search filters I found the http.favicon.hash quite useful, as it allows you to find sites with the same icon, which often means they are the same application. This made me wonder where the number comes from, and one thing led to another making me the proud owner of (currently) the only site that comes up when you search for 1337 on Shodan:
What is the favicon hash?
"Favicons" are useful on the web to quickly recognize sites, and can be found using the /favicon.ico path, for example:
https://jorianwoltjer.com/favicon.ico
Shodan is a search engine for all kinds of internet-connected devices, as it regularly scans the entire internet on various protocols, like HTTP. These can then be filtered to find specifically what you are looking for without having to scan the whole internet yourself. Filters like http.title:"something" that can query the <title> of a site, or http.favicon.hash:81586312 to find all servers that return a specific favicon that hashes into 81586312, which should be unique. This is very useful for finding well-known applications like Jenkins, and collections exist full of different hashes for these applications.
In 'Pivoting with Property Hashes' Shodan explains that it is a numerical hash, but not how it is implemented. A recent blog post from them ('Deep Dive: http.favicon') does explain the details of the algorithm, which are pretty simple: After finding the website, the raw favicon response data is base64-encoded into a string like this:
AAABAAIAEBAAAAAAIABoBAAAJgAAACAgAAAAACAAqBAAAI4EAAAoAAAAEAAAACAAAAABACAAAAAA\n
AEAEAAAAAAAAAAAAAAAAAAAAAAAA////Af///wH///8B////Af///wH///8B////ASWX/RUne/MX\n
////Af///wH///8B////Af///wH///8B////Af///wH///8B////Af///wH///8B////ASan/EEn\n
bvThJm/05yai/EP///8B////Af///wH///8B////Af///wH///8B////Af///wH///8BJqP8Ayaj\n
/I0mi/v5J1Tt/SdT7Psmi/z5JqL8j////wH///8B////Af///wH///8B////...
Important to note here are the \n newline characters that show up every once in a while. These are inserted at every 76th byte for some reason. It turns out this follows the RFC 2045 from MIME, used primarily in email protocols. This finding means that there are probably existing libraries out there that implement the specific encoding with newlines if we include "RFC 2045" in the search term. Python's base64 is one of them. Then the article tells us that MurmurHash3 is used to turn this long string into an integer:
# Downloaded from 'https://en.wikipedia.org/favicon.ico'
=
= # RFC 2045
= # MurmurHash3
# 857403617
If the goal is to craft an image that hashes into a specific number like 1337, called a "preimage", this algorithm makes it a bit difficult as it is not simply reversible. Firstly, a hash is a one-way operation, and the encoded bytes also make it hard to perform more advanced attacks as we cannot control raw bytes, only their encoded base64 alphabet. It seems like there is no other option than brute force.
32 bits is not a lot
First, let's estimate how long a regular brute force attack would take. We would keep altering the image slightly, maybe adding some bytes at the end, and each time check if its hash is equal to 1337. Because MurmurHash3 outputs a 32-bit hash from any number of input bytes, on average, we should find a match every 2³² ≈ 4 billion attempts. This sounds like a lot, but computers nowadays are fast, really fast. CPUs run at Gigahertz (GHz) frequencies, they run multiple billion instructions per second. If the hash has a small number of instructions, it should be doable to exhaust this whole search space in a relatively short amount of time.
So let's try it! The algorithm seems pretty simple to implement in a fast language, but we can also use existing pre-optimized implementations for the language of our choice. For this project, I decided to use Rust because of its speed at runtime, and ease of writing compared to other fast languages like C. We will make a simple implementation that computes the shodan hash, and then benchmark it to make a realistic estimate.
The murmur3 crate already implements MurmurHash3, so we won't waste time on that. For the weird Base64 with padding we can find a b64 crate that has a flexible configuration allowing padding and newline insertion while encoding. It allows us to add a newline every 76 characters, but we also must remember that the file ends in a newline too. The library cannot do this, so we'll add it manually. We create a shodan_hash() function that performs the hashing inside a src/lib.rs file so that other code can use it too. It will be defined like this:
// Add dependencies with `cargo add b64 murmur3`
use ToBase64;
use murmur3_32;
use Cursor;
pub const BASE64_CONFIG: Config = Config ;
Then in the src/main.rs file we can test it by using the function on a local file:
To test if it works correctly, we can take a known hash from shodan-favicon-hashes.csv, like Jenkins, and download the original favicon.ico file too from the github repository. Running it with this file in the same folder, we get the correct hash just like in Python!
)
Now we can benchmark this naive implementation to see if we need to optimize it further, or if this is fast enough. The criterion crate is a nice micro-benchmarking library that we can give a function, and it will run that many times to measure its speed. We'll add the dependency and define the benchmark in the Cargo.toml file:
...
[]
= "0.5.1"
[[]]
= "bench"
= false
Then we implement it in a benches/bench.rs file in the root folder. Criterion requires a little bit of boilerplate code, and we need to be careful to use black_box() around our data to prevent the Rust compiler from optimizing away the static bytes in data, and possibly pre-computing the result. This benchmark will then look something like this, importing the function we just made:
use ;
use shodan_hash;
criterion_group!;
criterion_main!;
Running the benchmark on my own laptop, we get these results:
time: [81.062 µs 85.762 µs 90.802 µs]
That means every iteration of this function on the whole favicon takes only 85 microseconds on average, only 1/11660th of a second. But with 4 billion iterations to do this is still a significant amount of time. It would take around 85.762 μs * 2**32 = 4 days to find a 1337 hash! This speed is not acceptable to me, so we'll need to get a little clever to reduce this.
From 4 days to a few seconds
We need to think about optimizing this, and so far the only thing it does is compute the hash of this single favicon many many times. We used the black_box() to prevent Rust from optimizing away the whole computation, but it kind of has a point. If we keep hashing the same data over and over again for each attempt, that is a lot of wasted computation. Hashing algorithms work on chunks of data at a time, and keep track of an internal result that is altered by the input bytes, and eventually returned when you want to get the hash result.
MurmurHash3 works on blocks of 4 bytes at a time, and if the first part of the input is always the same, we can just cache it! In theory we should only have to compute the bytes that come after the random part of the favicon, and if we cleverly put that at the end of the file, that would be the minimal amount of work for the hashing algorithm because we can optimize away everything before it.
We'll quickly take a closer look at the MurmurHash3 algorithm to see how easy this would be to implement:
https://docs.rs/murmur3/latest/src/murmur3/murmur3_32.rs.html#28-72
This is a very simple algorithm, and that is also the reason it is so fast to execute. Most of the time will be spent in the 4 => { case, which changes the state and processed variables. If we ever want to skip to a future state, we just need to save and remember these two variables and set them again. We cannot easily get these variables from the finish() output, but if we alter the code slightly we can do as many 4-byte iterations as possible, and then return the state and processed variables to continue later.
Then we will have to change the murmur3_32() function slightly to accept a processed variable at the beginning as well as the state which is already possible with seed. Then only the last part of the hash needs to be computed with the small amount of random bytes. It's easiest to just copy the murmur_32.rs file into our own project and change it from there with our new features:
/// New: Return the last intermediate state if the input only contains full 32-bit (4-byte) chunks.
/// Changed: to have a `processed` variable as input
This now allows us to compute the MurmurHash3 of some 4-byte aligned data, and then brute force the last little part. We'll implement it and at the same time add some multi-threading into the mix to significantly improve the speed. Computations are not reliant on previous results, so they can be computed at the same time on multiple cores. In Rust, the rayon crate does this beautifully and allows super easy implementation of this with parallel iterators. To generate random bytes that might give the target hash, we can just iterate an integer and turn it into bytes:
use ;
use ;
After only a few seconds of running this with cargo run --release, we get a hit:
)
# It takes 4 real seconds to run
# Without multithreading, it would take ~40 seconds
To confirm it, we should try to compute the hash of that data using Python again:
>>>
>>>
1337
Perfect! Our technique works, and fast too. Much better than waiting for 4 days.
While this proof of concept is already cool, the goal is to make a favicon with the shodan hashing algorithm. That means we should use the favicon as input, and append bytes to that, which is made simple because browsers don't care about extra bytes after the file and will just try to render it. To brute force the actual Shodan hash algorithm get still need to include the Base64 part before hashing the data, meaning that our random bytes need to be valid Base64 characters as well because we only have full control of the data before encoding.
Alignment gets tricky
Keep in mind that the intermediate calculation only works on bytes aligned to chunks of 4, which sounds perfect for Base64 because it is also always aligned to 4 chunks of bytes in the output... But the problem comes when we introduce the RFC 2045 newline characters that the algorithm requires. For every 76 bytes of output, 1 extra byte is added, misaligning everything that comes after it until it is misaligned back to the original offset of 4 bytes. We can try to get clever with calculating this and handing weird padding cases etc., but remember that this code is only executed once right at the start of the program.
That means we don't need to optimize it and an option is to just keep making the input longer until the alignment happens to work out. Then we compute its intermediate value like normal, and for the brute force, we also need to encode the random bytes we iterate over. This will make the brute force a little slower but it should not be too bad on only 4 bytes of input at a time. Then we again reconstruct the favicon with the random bytes we generated, which will be the Base64 version of the result. We can manually decode it to get an actual favicon back:
use fs;
use ToBase64;
use ;
use ;
Running this final version takes a bit longer, but after a few seconds, it finds a bit of Base64 that results in the 1337 hash!
)
To verify that it works as expected we can throw it into Python again, and its decoded version too:
>>>
>>>
1337
>>>
>>> =
>>>
1337
Perfect! Now we have generated a working favicon that has the shodan hash of 1337. This can be put on an external IP address with a web server under /favicon.ico, and when Shodan scans your server, it will compute and store this hash.
Conclusion
In the end, this was a very fun project to do. From seeing the small number and thinking if that would be brute forcible, to researching the algorithm used, and finding a massive optimization by caching the state of input data that won't change.
To make it all easier to understand and do, I made a simple CLI tool that implements the above method with flexible inputs, which you can find on GitHub here:
https://github.com/JorianWoltjer/shodan-favicon-preimage
It's worth noting that this same hashing algorithm is not only used for favicons, but also other data like response HTML or headers. It is also possible to generate a hash equal to 0 which is normally used on Shodan to filter out empty data (eg. with http.html_hash:0), but you can hide in that data with a filled response having a hash of zero. Have fun!