While this post was placed in an "XSS" folder, this time around Intigriti published a challenge where the goal was full RCE! There was still a solid client-side component, which is my forte, so there is no need to fret. This is your last chance to play it yourself at challenge-0625.intigriti.io.
In this post, you'll also read about a hidden danger in Chromedriver which I've played with a lot in the past few months. I'm sure it is applicable in many, many other scenarios to escalate from XSS to RCE in selenium. This challenge was quite a 🎢 so I've included some ideas that barely didn't work too.
Source code was given for the application with a Dockerfile to easily set up a local instance. I added a simple docker-compose.yml file to start/stop it easily. A little later on I also wanted GUI access, on WSL this can be done with the following volumes: and environment::
services:
web:
build: .
ports:
- "1337:1337"
volumes:
- /mnt/wslg:/mnt/wslg
- /tmp/.X11-unix:/tmp/.X11-unix
environment:
- DISPLAY=${DISPLAY}
Then start the container like so:
The Bot
While this isn't specifically an "XSS" challenge, there is still a Chrome browser bot using selenium that visits any URL starting with http://localhost:1337/.
return
...
=
return
...
=
=
This bot seems quite useless so far, we don't get anything from the response, it has no authentication and the URL must be on the trusted host. We'll have to dig a bit deeper at the application before we find a use for this process.
On the main application, you can store notes. There is a trivial Self-XSS in their content when saving a note with an XSS payload like <img src onerror=alert(origin)>. It's triggered by the following sink:
The problem is, fetchNotes() is only called after some interaction or if (currentPage === "/index" || currentPage === "/"), both of which are impossible because the vulnerable notes.html is only returned for /notes and the bot, as we noticed, doesn't do a whole lot. We can't even get the bot to our domain and the login isn't vulnerable to CSRF. This is unlikely to work.
Instead of messing more with this, I focused on the other endpoints out there, most require you to be logged in and have an unusual "instance_id" mechanism. Every endpoint (eg. /api/notes/upload) is wrapped like this:
=
...
return
Logging in can easily be achieved through registering and the /api/login endpoint, but note that we cannot register a username with "invalid characters":
return
=
=
=
=
return
...
...
=
return
return
The Instance ID mechanism works as follows:
return False
=
return
return
=
=
...
=
return
return
Essentially, if we already have a session with an instance, it returns that. Otherwise, it will be taken from the INSTANCE= cookie, and as a last resort, it just generates a new UUIDv4, saving it to the session. A session may not be valid if the directory it points to does not exist. Notably, no sanitization takes place in this check, allowing for paths like ../../../../../etc pointing to /etc to end up being "valid".
In every response, it sets the INSTANCE= cookie again to the value it used during its execution.
The instance_id value is used in some function bodies, so a fair question is whether we can control it. To do so, we need a session without one and then set the cookie to any arbitrary value, which saves the value to our session for future use. While logged in we already have a value for it, so we should do this while not being logged in yet, then once we do, the values merge. We can hit the /api/notes/upload (which requires log-in) with any value for instance_id.
Arbitrary* File Write
We'll now take a look at the implementation of uploading files because this type of functionality is easy to mess up:
=
return
return
return
=
...
=
# [0] File size limit
return
# [1] INSTANCE_DIR + instance_id + "notes"
=
# [2] + sanitize_allow_dot(username)
=
# [3] + sanitize_allow_slash(filename)
=
=
...
At [0], we see one restriction we won't face too much trouble with. [1] is where it starts to get interesting. The code joins a static "/app/instances" with our unsanitized input, instance_id, allowing us to completely negate that first path using ../ sequences. Then the "notes" directory is added to our input, followed by our username at [2]. Remember from the registration, the username is sanitized to only allow simple alphanumeric characters, but interestingly, it still allows dots (.). Finally, at [3], our filename from the upload is added to the path while being sanitized to only allow alphanumerics with slashes.
So, we can create a path like "/app/instances" + "../../tmp" + "notes" + username + filename. It may look like we're stuck to a directory named notes because our unsanitized injection is before that input. However, the username validation barely allows us to set it to .., undoing that directory and finishing it with the filename. Our final injection will be resolved like this:
- instance_id:
../../tmp, username:.., filename:test "/app/instances" + "../../tmp" + "notes" + ".." + "test"/app/instances/../../tmp/notes/../test/tmp/test
The following scripts this idea to write whatever we want anywhere* we want:
=
=
=
=
=
=
=
, = ,
Running it, no errors seem to occur, and checking inside the container, we find our written file!
I put an asterisk after "anywhere" because the filename sanitization limits names to match [A-Za-z0-9_], so no file extensions are allowed with . blocked. This makes it slightly harder to find a good target to write to. One thing that I quickly targeted was the chrome_profile directory that this challenge creates for every instance to run the bot in. We can write and even overwrite files in Chrome's user data directory, I'm sure there's a way to make use of the bot that way.
The directory is only filled after running the bot once, so we'll trigger it with a simple http://localhost:1337/ URL and explore the filesystem:
From this small adventure we can gather that the Default/ directory is where the juice lies, we see various types of storage we can mess with, as well as some configuration files like Preferences. The content of this file is a giant JSON collection of the user's settings:
I've left out a lot of other values, this is just to show you that there's some really interesting stuff in there. The filename Preferences doesn't have a . in its filename, so it's a great target for our Arbitrary File Write! We should check what settings can help us in the scenario that the bot opens http://localhost:1337/ and does nothing else.
If you've configured the GUI through your Docker container, the following command should open Chrome while saving data to your instance.
Browsing through the settings, one that first stands out is the option to add a startup page:
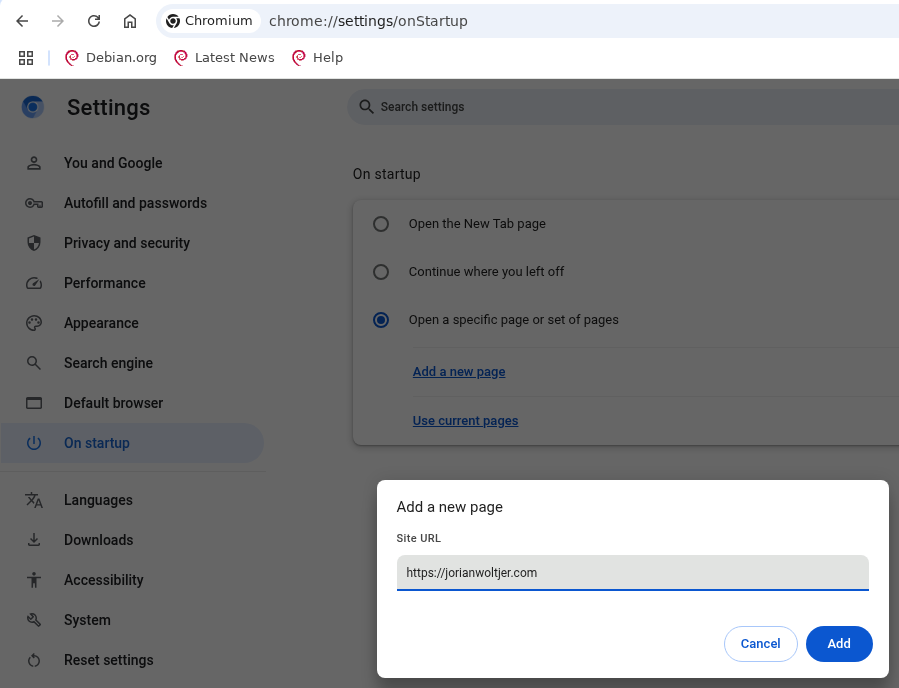
After configuring it, we can look for its value, using gron to easily find the JSON path:
| |
;
;
;
;
;
There we go, it appears that there is a key named "session" containing "startup_urls" set to an array that includes "https://jorianwoltjer.com/" now that we configured it, along with a "restore_on_startup": 4 value presumably enabling it. If we set this to a webhook on which we can monitor requests, triggering the bot of this edited instance now also triggers the webhook because the startup sites are opened!
Let's write this into our PoC:
=
=
=
To run it, we'll create a new account and instance by clearing our cookies, then trigger the bot at least once. Putting the instanceId in our new script, it overwrites the Preferences successfully, and starting the bot again triggers our webhook as expected:
HTTP/1.1This feels like a huge start, we can now start to attack the application for XSS, but what would XSS even get us at this point? Maybe there are more settings out there that would help gain code execution right away.
Failed ideas
The above was done in around 2-3 hours, but this is where time really started to stack up for me, trying many ideas before the correct one. Still, I think it's useful to explain what they were and why they barely didn't work.
Firstly, a super simple check is to see if we can overwrite any files that are executable, to create a binary payload:
Nope, 0 results. We'll have to get more clever. I remembered another potential path to RCE through the browser: Native Messaging for Extensions. It spawns a process and then communicates back and forth with STDIO. An obvious requirement for this is a malicious extension, so I went and tried to copy over the Extensions/ folder from an instance where I manually installed one to a fresh profile. This surprisingly worked, and it loaded the extension on the fresh profile by only copying some small files.
However, that euphoria was quickly shut down by the realization that the get_chrome_options() function defines many non-default options:
The --disable-extensions option prevents our amazing extension from being loaded. But I had a trick up my sleeve, I knew there were some "built-in" extensions in Chrome for functionality like previewing PDFs, would even those be disabled now? Checking chrome://system shows that no, they are still loaded somehow!
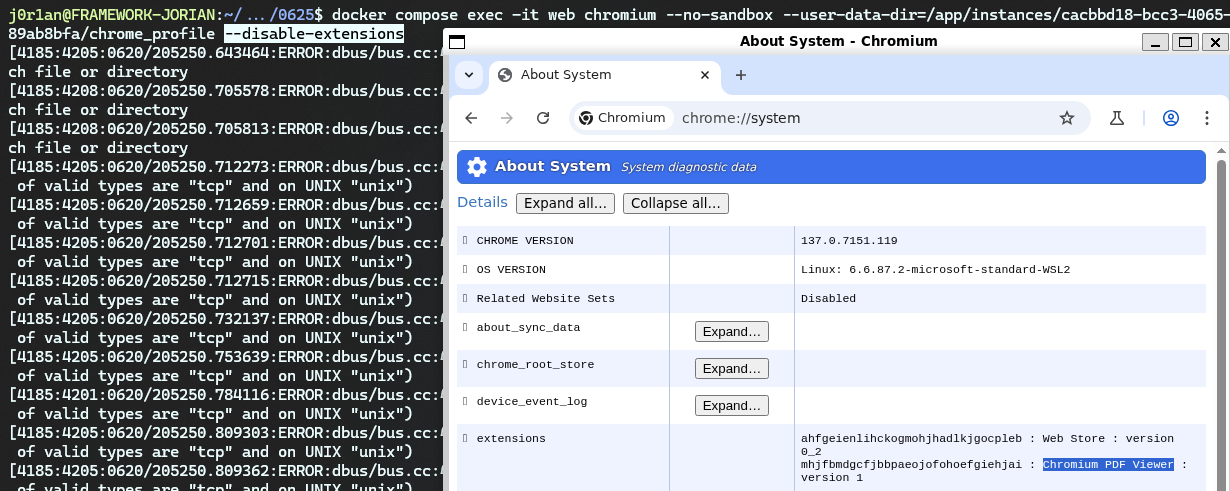
We can even see these extensions in the Preferences file and have the ability to change things like their manifest, and "path" where to load them from. I tried messing a bunch with trying to get a custom extension to be loaded through this mechanism but without luck, it seems to get these extensions from another place.
This is where my idea of using extensions officially died.
I then looked into potentially using a handy CTF trick to turn XSS on localhost into RCE in selenium, which I'll explain in detail in the last chapter of this post. For now, just know that our goal is to get XSS on the http://localhost:1337 origin.
My first idea was to write fake Cache/ entries for the origin to respond with an XSS payload on the origin. However, it seemed hard to restore from the disk cache without causing a revalidation, and the disk cache format itself was too much to handle for me.
Another closer attempt was installing a permanent Service Worker in the Service Worker/ directory, which seemed a lot simpler. It would allow me to execute code in the target's origin while only requiring a few small files. This all looked great until I noticed it required paths containing impossible - and . characters:
Service Worker/
├── Database/
│ ├── 000003.log
│ ├── CURRENT
│ ├── LOCK
│ ├── LOG
│ └── MANIFEST-000001
└── ScriptCache/
├── 2cc80dabc69f58b6_0
├── 2cc80dabc69f58b6_1
├── index
└── index-dir/
└── the-real-index
One last small rabbit hole was trying to overwrite the SQLite database, a sleep-deprived Jorian didn't notice that /app/instances/default.db also just contains a . making it impossible from the start. Before noticing this I tried making a database file small enough to be under the 20KB limit since by default it's already 24KB. After some looking around I saw I could change the default page_size from 4096 to 512 in order to make small rows take up less space:
PRAGMA page_size=512;
VACUUM;
This worked wonderfully, turning the whole file into only 4KB, but as explained this whole path was impossible from the start. Still learned something new though!
These were my best ideas, but in the end, sometimes you just need a break. I took one and once I came back, thought of a much simpler solution that just works.
HTML Download to XSS
The idea is that we can potentially alter the existing HTTP server with our Arbitrary File Write. This initially doesn't look very useful, while we can write to paths like /app/static/anything, we cannot write anything with extensions (. is blocked in filenames). If we could, a simple .html file would do the job of giving us XSS. Can we escalate our basic file write to a stronger one with file extensions using the browser?
From extensive browsing experience, I know that browsers automatically download files to your Downloads/ folder, it may be a long shot, but could there be a setting that configures the directory to be anywhere on the filesystem?
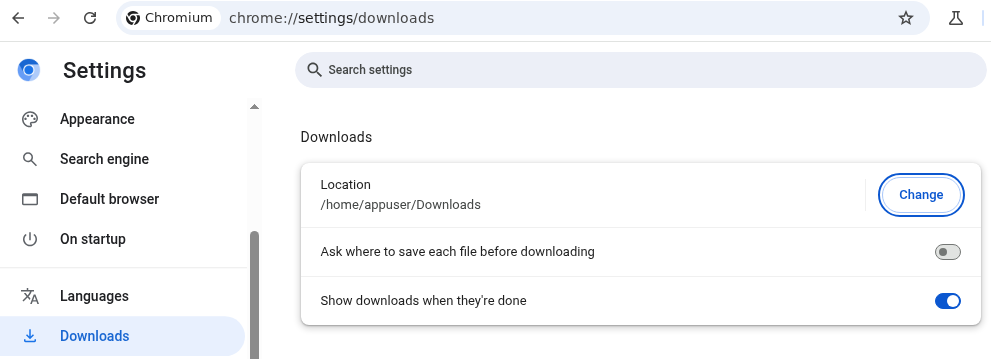
There sure is, and even better, inside of Preferences this is a simple "download": {"default_directory": "/home/appuser/Downloads"} key we can overwrite! Setting this to /app/static would place all downloaded files into that directory with their default name. You can set up a simple server that triggers a file download when visited using the Content-Disposition: header (finally, it's useful to us hackers for once!):
We can host it with php -S 0.0.0.0:8000 and then use the "startup_urls" from earlier to make the bot open http://host.docker.internal:8000. The next time the browser starts up, it will download our file. This works great for "safe" files like .txt, but seems to have some sort of protection against .html files, it adds a .crdownload suffix:
I was a bit afraid the idea of downloading HTML files for XSS also also wouldn't work at this point, but just to be sure, I decided to open the browser instance in the GUI. This quickly revealed the problem:
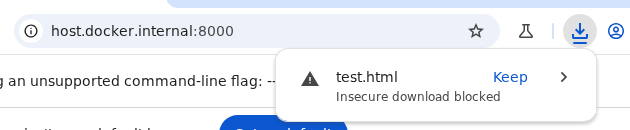
The word "insecure" reminded me of HTTPS, maybe it just doesn't trust the combination of HTTP + HTML? We can easily host our local service through HTTPS using a public service like Cloudflare Quick Tunnels, then trigger it again:
| ) |
| |
Perfect! It successfully downloaded the raw .html file, which is now accessible through http://localhost:1337/static/test.html, also for the bot. Had we written a malicious XSS payload in the file we would have XSS on the http://localhost:1337 origin.
Chromedriver CSRF to RCE
So, we have XSS, what was my secret plan with this? I'll say this one time and one time only for the CTF authors:
>>> XSS on any localhost origin makes RCE possible on selenium! <<<
It all comes down to Chrome issue 40052697, marked as "Won't fix". Some background you need to understand is how chromedriver works, it's how some libraries can automate Chrome to perform certain actions. Most libraries opt for the alternative "CDP" (Chrome Debugging Protocol) instead. But selenium uses it by starting chromedriver as follows:
|
A --port=RANDOM_NUMBER argument is added which ranges from 32768-60999 (uses /proc/sys/net/ipv4/ip_local_port_range, so might differ if configured). It opens up an HTTP server implementing the W3C WebDriver spec with endpoints like /session to create a new browser session via a REST API.
From the issue above we can gather:
- It is possible to achieve Remote Code Execution on
/sessionby providing a maliciousbinaryandargs - The request needed to create the new session is a CORS Simple Request, allowing any origin to send it. While the body is JSON, the
Content-Type:isn't checked - The origin check allows any "localhost" origin to access it
This combination allows a malicious script on http://localhost:1337 to send a CSRF request to http://localhost:44695/session and start a new session, with an arbitrary shell command to execute. We just have to find the port through some light brute force.
This issue was first shared with me by @piprett, a Norwegian CTF player who learned the trick from @mar4e during their national competition. While discussing the solutions he shared the code snippet with me which blew my mind, and caused my evening to vanish. After a bit of reverse engineering, it yielded one of the most powerful 🧀 strategies I've seen for client-side challenges.
Here is the final clean payload:
Back to our challenge, it's easy to connect the dots now. Just host this as our XSS payload and let the bot trigger it (may require a few attempts because the 15s timeout shuts it down before the end of the loop, you have to get lucky with a low port). After triggering it, sure enough, we find our RCE result:
All that's left is doing everything in order on the remote https://challenge-0625.intigriti.io instance, then collecting our flag in /flag*. The following gist contains all the necessary files and a script that executes the steps explained in this writeup (with some TODO comments if you want to reproduce it):
https://gist.github.com/JorianWoltjer/be7c7c0dd6d3529dbe10f284b4e837a5
If all of this got you excited about what other kind of tricks are possible in Headless Browsers, I've just added this and a few more to my Gitbook: 🌐 Web / Client-Side / Headless Browsers!