Intigriti hosts monthly challenges where you must find a difficult XSS vulnerability in some source code. This month @joaxcar made an awesome one that's fully client-side, but still involves some cool new tricks.
Let's not waste any more time and jump right in!
The Code
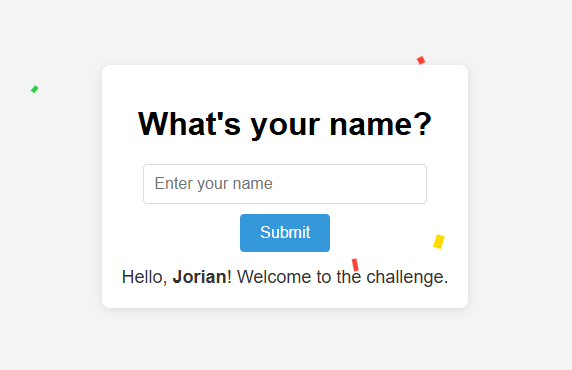
The challenge starts at /begin. We input our name, press Submit, and are greeted with a hello message after a fairly slow spinner. Oh, and confetti! 🎉
We can hit Ctrl+U to look at the page's source code and find that all the logic is hidden away in /script.js. I normally have to truncate some of the code, but this one was nice and short, so enjoy the full thing:
// utils
// main
;
Let's follow the code. Under the // main comment, it defines a function that it instantly calls at the bottom with ();. The query search string is parsed using URLSearchParams(), which is a very standard way, of which I already know pretty well how it works. When getting the value of a parameter using .get('name'), it will be a string URL-decoded. It can't be an array; even if we have multiples of the same parameter, the first is always returned.
The name is matched against a Regular Expression that seems only to allow alphanumeric characters and whitespace. RegExes should immediately trigger your alarm bells, as so much can go wrong with them, this challenge being no outlier. When it passes through this check, the value is passed to a /message?name=... request that retrieves some HTML, presumably based on the name. Finally, the response is sanitized by DOMPurify and set as the .innerHTML of the <div id="message">.
All the way at the bottom of the code snippet, a strange requestIdleCallback(addDynamicScript) is called. The (limited) documentation says that the given callback function will be called some time in the future, when the browser thinks it's "idle". We'll get to understanding this deeper later in this challenge.
Note that these things don't necessarily happen in order because the fetch() is async, and it defines an inline function that will be called once it gets a response. The rest of the code will immediately continue.
When that addDynamicScript is called, it looks for window.CONFIG_SRC?.dataset["url"], a very unusual place to look for a URL, and one that isn't even used by the web application as we see it. The default is just a /confetti.js script that will trigger once our message is placed.
It performs another interesting check on this URL using safeURL(), which normalizes the URL to an absolute one using the URL() constructor. If the origin is the same as the current one, it's added as a script source. This sounds like a gadget that could allow us to execute arbitrary JavaScript, as is the goal of this challenge.
We've seen the code, now we gotta crack it.
Regex Bypass
I alluded to Regular Expressions being dangerous, right now we're looking at:
/([a-zA-Z0-9]+|\s)+$/
Every symbol has a specific meaning. Use tools like Regexper to understand everything and RegExr to test ideas. Here we see that our string must follow the pattern of "any number of alphanumerics, then the end of line". One common mistake is using a partial match when you really need a full match. Here, the $ checks that everything up against the end of the line is in fact alphanumeric, but says nothing about the start of the line (^)!
This means we can start a string with any characters we want, and the .match() function will only care about the end. The following will still bypass the check:
x
Note the x at the end to match any alphanumeric character at the end, which is what the Regex wants. We can now get special characters into /message?name=:
https://challenge-0525.intigriti.io/message?name=%3Cimg%20src%20onerror=alert()%3Ex
Hello, x! Welcome to the challenge.
Awesome! It seems our payload is unescaped, so it will be interpreted as literal HTML. Although looking back at the code, the response body is passed through the default and up-to-date DOMPurify first. This prevents the XSS payload we put in from executing directly.
DOM Clobbering
DOM Clobbering is an attack with a funny name, but one that can really come in clutch in situations where we can't directly get XSS with our HTML injection. The idea is to abuse a weird feature of JavaScript (one of many) in browsers where HTML elements are accessible via a shorthand by their id= on the window object. Let's look at an example:
In our case, we can notice the following "gadget":
The window.CONFIG_SRC can refer to <img id="CONFIG_SRC"> if we create it in the DOM! We have an HTML Injection with DOMPurify, and it won't see a simple id= on an image as malicious, so it will allow this to pass through.
To do something useful, we want control over the url variable. The .dataset["url"] is taken from the element. .dataset properties refer to data- attributes on the HTML element, so we can make one named data-url with any value of our choosing to control it.
We can inject this into the challenge by visiting the following URL:
After visiting and letting it load, window.CONFIG_SRC?.dataset["url"] seems to contain our URL as expected. We can now try to set a breakpoint inside addDynamicScript() to see when and how it executes:
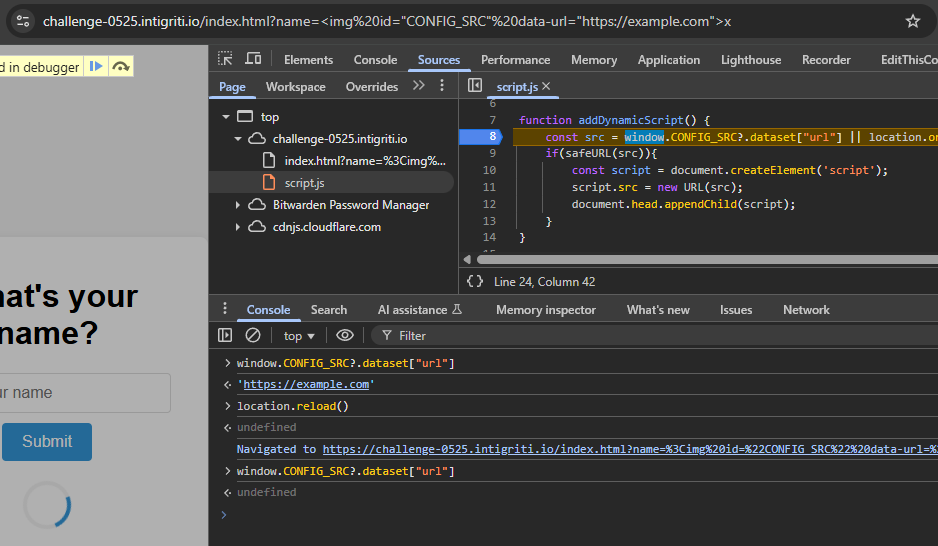
Huh? We instantly hit the breakpoint, and while stepping through, we notice that our beautifully clobbered URL is EMPTY. If we let the breakpoint continue and check again, it is there. We can conclude that we are not fast enough.
Race Condition with requestIdleCallback
The callback triggered by requestIdleCallback() runs very quickly, while the fetch() for our injected HTML response takes 2+ seconds. This is a problem, and to rearrange the order, we need to either speed up the fetch or slow down the callback.
I first looked at speeding up the fetch. The endpoint seems intentionally slow, but through caching, we may get a speedy response straight from the browser. Browser caching sometimes happens automatically to speed up future requests, we should look at the response headers of the /message endpoint to determine if it's cacheable or not:
HTTP/2 We're looking for Cache-Control, Expires, or Age, but no such headers are given. These normally tell the browser how and for how long to cache a response. If it is not told how to, it will use some heuristics to make an educated guess. There are two states of a cached response that are important to understand:
- Fresh: The response will instantly be returned without checking if it's still the same on the server.
- Stale: When a response may still be valid, but it is first validated with the server with an extra low-bandwidth request
For heuristics without any headers to base an age off, the best it can do is create a stale cache entry for the response. That's why you'll see requests with If-None-Match: headers and a 304 status code when visiting it multiple times. Without cache control headers, this will always happen before returning the cached entry. This means we still have to wait for that 2+ second delay for the fetch.
If we can't speed up the request, we'll have to somehow slow down the callback. There is little to find about "requestIdleCallback" online, except for a useful figure in the specification:

After input processing, rendering and compositing for a given frame has been completed, the user agent's main thread often becomes idle until either: the next frame begins; another pending task becomes eligible to run; or user input is received. This specification provides a means to schedule execution of callbacks during this otherwise idle time via a
requestIdleCallback()API.Callbacks posted via the
requestIdleCallback()API become eligible to run during user agent defined idle periods.
From this, we learn that if there is a period in a frame where the browser is not doing anything, idle callbacks may be triggered. In a simple web page as this, the browser must have a lot of idle time at the end of each frame and can run the callback almost instantly after it's registered. We need to slow this down.
A simple idea is to just fill the browser's renderer with so much computation that it can't hold a steady 60 FPS, but instead has to use more than the entire available milliseconds per frame. This would leave no room for the idle callbacks to be executed; just what we want.
;
While running the above, we can test how long it takes for idle callbacks to be triggered:
// Register a callback every 100ms, measuring how long until it triggers
;
Trying it in our browser, we find that there are no callback logs at all after calling busyWait()!
But... we hit problems when trying to do the same with the remote instance. It's possible to iframe it and then run the slow JavaScript on our attacker's page in hopes of slowing down the frame, but this doesn't happen.
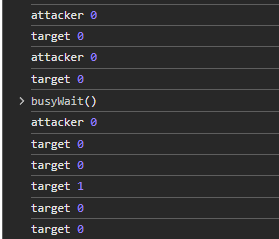
Logging both the attacker's overarching page and inside the iframe, only the attacker's process is blocked, and the target still goes on as if nothing happened. This is due to process isolation, different frames can run in different threads, especially when they are cross-origin. We need to slow down the target page using the target's origin itself, maybe in another iframe.
An idea that comes to mind is using our DOMPurify HTML injection to do some very heavy rendering to slow down the page. <style> tags are still allowed, which makes it easy to apply heavy styles to the document, and slow down the whole process, including other same-origin iframes like the one we want to race condition. The following styles accomplish this:
{
0% }
100% }
}
}
The large animations slow down the browser a ton, and while this is going on, we can load the target page in another iframe. Because the same process will be used for this same-origin frame, it will also slow down. The fetch() is triggered and the callback is registered, but there is no time to run that callback yet. After a bit, the fetch gets a response and writes it to the DOM, and we can remove the original laggy iframe. This brings the browser back up to speed, allowing it to trigger the callback and our gadget, with the clobbered DOM!
const = ;
;
This works in Chrome. After the whole ritual finishes, a request is made to /anywhere to be executed. But unfortunately, this doesn't seem to work on Firefox. It's not as impacted by the CSS, and somehow still finds time to execute idle callbacks.
I tried many variations of heavy CSS targeting Firefox, creating pretty pictures, but nothing that led to fewer idle callbacks. This steered me towards a slightly different approach: making the JavaScript busy just like our earlier busyWait() (which did work on Firefox).
It turns out that the Regular Expression validating our input has another problem: it is vulnerable to "Catastrophic Backtracking" or ReDoS (Regular Expression Denial of Service). You can easily check this using an online tool, which also generates a proof of concept:
.Running this indeed hangs the browser for a while, and we can trigger this using a malicious name input. No need for crazy CSS anymore, and this time it works on Firefox as well!
https://challenge-0525.intigriti.io/index.html?name=00000000000000000000000000000000%21
Well, this way of lagging the process is quite different from the CSS we had before. It continuously prevented the idle callbacks from triggering while allowing other JavaScript to run every once in a while. The ReDoS is a one-shot; it takes very long once, but while doing so, it leaves no room for the fetch() we want to happen. However, if we can just thread the needle between having started the fetch and waiting for the first frame to return for the idle callback to trigger, we can stop the process until the fetch is resolved, and then let it continue again.
We need to race the race condition, but this time we can make it easier for ourselves. By spawning 100 iframes all performing a race, we only need to win one. While loading the 100, we will spawn 1 that acts as a lag frame, stopping all others from loading. Hopefully, at least one will be perfectly timed so that the request comes back before the idle callback has a chance to trigger. Below is an implementation:
Now, on both Chrome and Firefox, we have a consistent way of loading any same-origin script using DOM Clobbering.
URL origin validation bypass
To remind you, this is the check we're up against:
Now comes what is, in my opinion, the coolest part of the challenge, because at the start I genuinely believed it was impossible. What convinced me to start looking deeper into it was that the same check could easily be implemented using a CSP, and the author of the challenge, Johan, loves CSPs.
The safeURL() function parses the URL using URL() with a 2nd argument, the base. The base will be used if the URL is a relative one to fill in the origin and path. For example:
new.
// 'https://jorianwoltjer.com/'
new.
// 'https://example.com/relative'
new.
// 'https://example.com/some/base/relative'
If the .origin of this parsed URL is the same as the challenge page's origin (https://challenge-0525.intigriti.io), it is considered "safe". Then, the URL is parsed again, without a base this time, so it must be an absolute URL. This is then inserted as a script tag into the DOM.
This makes the goal clear: find some difference in the relative and absolute URL parser so that during the check, it is the challenge's origin, but during the use, it is a malicious one that we control. There is a specification on URL parsing if you're into that, from there I noticed it basically first sets all parts of the base URL for the resulting URL, then only alters it by the relative URL for whatever parts it finds. There is a lot of detail in the specification that can be hard to understand, so in cases like this, opting for straightforward fuzzing can be a better option.
We can take some special characters and keywords common in URLs and confusions to check if any of them cause a differential in the origin if parsed in these two different ways.
The first step is to recreate the check in a simple function to verify if we've found the holy grail:
We ignore errors because much of our crazy syntax won't be valid URLs, and look for when the origins of both ways of parsing differ.
Then all that's left is collecting some parts of the URL and joining them in many permutations:
let =
;
Running this in the context of https://challenge-0525.intigriti.io/index.html, we quickly get many hits, such as:
https:example.com=> https://challenge-0525.intigriti.io https://example.com
Seriously? We simply remove the // from our URL, and the relative parser sees it as a path, while the absolute parser sees it as a regular full HTTPS URL?
new.
// 'https://challenge-0525.intigriti.io/example.com'
new.
// 'https://example.com/'
This is perfect for us, because we can now just set data-url= and point it to our server to return arbitrary content:
Hosting this on an attacker's site and leading a victim to it, a bunch of iframes will load, and after a few seconds, one will win the race and load our injected script, triggering the XSS!
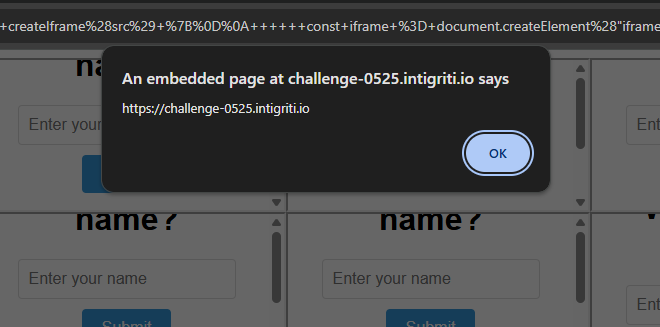
GG. While the inconsistency around CSS performance annoyed me a bit during this challenge, the cool URL parsing bypass made up for it, showing that the quirks of JavaScript and browsers in general never seem to end.