Every month Intigriti hosts an XSS challenge. The goal is to find a hidden Cross-Site Scripting (XSS) vulnerability in the given challenge. I saw there was a new challenge on Twitter. I was just learning about the technique needed for the challenge a few weeks ago, so it was cool see my learning really payed off. In the end, I solved it relatively quickly within a few hours of the release.
The Challenge
Before I spoil the challenge and its solution, you can still try it yourself on https://challenge-0522.intigriti.io/ to see if you can solve it. It's a really good challenge for practice.
When we load the page there is an iframe loaded on the bottom. This iframe is the real challenge we need to look at. Looking at the HTML we see that it links to challenge/challenge.html. We can just visit this page to see it on full screen. We are then greeted with the challenge:

There are a few buttons/pages on the navigation bar, and the text on the home page is talking about pollution.
"Pollution is consuming the world. It's killing all the plants and ruining nature, but we won't let that happen! Our products will help you save the planet and yourself by purifying air naturally."
Knowing some stuff about Web Security and XSS, I quickly thought of Prototype Pollution. But we'll explore that in a bit.
Upon visiting the page we can also notice that it adds the ?page=1 query parameter to the URL. When clicking around to different pages we see that this number changes. If we look at the source code we can see where this is coming from. There is a <script> tag with JavaScript on the page:
var = ;
var = ;
The most important part here is the bottom few lines where it selects the page. It gets the ?page= URL parameter and selects the page from pages based on that. It then adds the content to the innerHTML of the page. It also just redirects back to page 1 if the page is not found in the pages variable.
With the innerHTML, we probably need to get our own HTML into there, with a <script> tag for example to execute JavaScript code causing XSS. But how do we get our own code in there?
Prototype Pollution
In the <head> of the page we can see a few external scripts being loaded:
Note: This inline script of
jQuery.querywas an external script before, but so many people were trying the challenge that the server hosting the script gave429 Too Many Requests. This caused the creator to just copy the code to an inline script so no requests were going to the external server hosting it.
I hadn't seen the jQuery.query script before, so I looked up what it was. When I searched "jQuery.query 2.2.3" I found that it's called jquery-plugin-query-object. In this challenge, I had a strong suspicion that we were going to need Prototype Pollution, so I searched "jquery-plugin-query-object prototype pollution". This quickly resulted in a Github page showing a Prototype Pollution vulnerability in this library. It was a Proof of Concept for CVE-2021-20083. The Proof of Concept looked like this:
?__proto__[test]=test
Fun fact: This Proof of Concept is actually part of a big collection of Prototype Pollution vulnerabilities in common libraries. I suggest you check it out to see some more real examples.
It seems that when parsing the query string this library can accidentally set the __proto__ property on an object. This is dangerous because this property is special. When values are set to this property, every other object also receives the property. Even when we create a new object with {}, secretly the property we set with the prototype pollution is set on it by default (you can read more about this vulnerability on HackTricks). Let's see this in action with the following URL:
https://challenge-0522.intigriti.io/challenge/challenge.html?__proto__[test]=test&page=1
Then if we open the console, we can execute the following commands to see if the pollution worked:
> var a = // Create an empty object
> a. // See the value of `test` was polluted
It worked! When we create a new empty object and access the test property it returns our "test" string. This also means we can set properties of objects that already exist. One interesting thing we can try is to add our own page to the pages variable. We can then specify our own HTML to be displayed on the page, and possibly get XSS.
The pages variable is just a dictionary with keys that get accessed with the ?page= URL parameter. So we can set for example the 1337th page to be <img src=x onerror=alert(1)>. Then we can access this page by adding ?page=1337 to the URL. Just make sure to use URL encoding for the = sign in the payload, because otherwise it will be interpreted as a parameter separator.
This shows half of our content like "<img src", but where is the rest, and where is our alert?! Well, it's not this easy. We still have the filterXSS() function that is run over our page content. This function seems to come from the js-xss library. In the <script> tag in the <head> of the page, we can see that it is on version 0.3.3. On the Github, I couldn't find any existing issues of this library that would allow us to bypass it. So we need to find something ourselves.
Bypassing the Filter
Don't worry, we don't have to find a 0-day in this library. Remember: We still have our Prototype Pollution vulnerability left to help us.
Looking at the Github page, I saw some examples with specifying options. In these options, we can whitelist tags and attributes to allow certain things to go through the filter.
// only tag a and its attributes href, title, target are allowed
var = ;
// With the configuration specified above, the following HTML:
// <a href="#" onclick="hello()"><i>Hello</i></a>
// would become:
// <a href="#"><i>Hello</i></a>
These options are normally given to the filterXSS(html, options) function as a second argument, which we can't control. But let's look at the source code to see how these options are handled. In the /dist/xss.js we find the main code doing the sanitization. Let's try following where the code goes when we call filterXSS(html) on some input:
This might seem weird because this function requires 2 arguments. In some programming languages, you're then not allowed to only specify one. But in JavaScript, if we don't provide the second argument it just gets set to undefined and goes on with the function.
So in here, the FilterXSS() function is called first, let's look at the one:
This function just seems to copy the options into the this.options variable. But the important thing to note here is that in our case options is set to undefined. The first line
options = ;
has the || syntax. This means that if the options value is not a truthy value, it will be set to {}. The undefined value is falsy, so it will be set to {}. This creates an empty Object, with properties.
Then right after in the code, we see the options.whiteList being set to options.whiteList if it is set, and some other values if it is not set. This is crucial because in the empty {}, it does not have the .whiteList property set. So if we pollute this value with something of our own, it will take that as the default value and we can add our own whitelist!
We just need to pollute the .whiteList property, with our own whitelist. Looking at the syntax example above we can try to recreate something like this:
var = ;
If we somehow provide these options as the whitelist, we can then use the onload= attribute on a <style> tag. A simple payload like <style onload=alert(1)> would then trigger.
To set these values with prototype pollution we can do something very similar to how we polluted the page itself. We just need to set the whiteList, then style, and again set the first element with 0 so it becomes an array. We set this value to onload so it is the only attribute it will allow. To do this we can add this to the URL:
&__proto__[whiteList][style][0]=onload
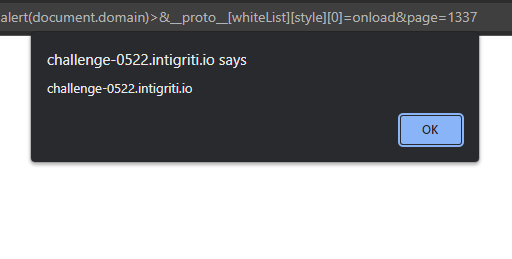
Then combined with the <style onload=alert(document.domain)> payload we can get our final URL (again make sure to URL encode the = sign in the payload):
When we click the link we finally get our juicy alert!
Root Cause of Prototype Pollution
It took me a bit to really understand Prototype Pollution because it's a bit of an advanced JavaScript feature. But after understanding it, I can see why this is a very important vulnerability to know. Developers rarely think about this when writing their applications, which is why this vulnerability exists in big repositories pretty often.
So why did this work? It's pretty interesting to look into why this worked because you'll learn how to find these types of vulnerabilities yourself in the future. If you remember we found the vulnerability from a proof of concept on Github. It also shows us the vulnerable code fragment. The vulnerability came from the $.query.get('page') line, so lets follow that function:
jQuery. = new;
...
var ;
...
queryObject.prototype = Whew, that was quite a big piece of code. I've added some comments in the most important parts of the code to make it easier to follow. The real vulnerability happens in the set() function where our input is set as a key to our object. The __proto__ then causes all objects to have the whiteList key, and eventually overwrites the normal whitelist of the js-xss library.
Luckily this vulnerability is fixed in the most recent version of jquery-plugin-query-object. We can look at the recent commits and find "Preventing prototype pollution". This fix just checks if __proto__ is anywhere in the parameter, and ignores it if so.
return target;
},
SET: function(key, val) {
+ if(!key.includes("__proto__")){
var value = !is(val) ? null : val;
var parsed = parse(key), base = parsed[0], tokens = parsed[1];
var target = this.keys[base];
this.keys[base] = set(target, tokens.slice(0), value);
+ }
return this;
},
set: function(key, val) {
Since our payload requires this __proto__ key to be set and thus be present in the string, this fix seems to be enough.
Conclusion
To summarize, we found a CVE in the jquery-plugin-query-object library to cause Prototype Pollution. Then to get XSS we needed to bypass the filterXSS() function, which we did by abusing the Prototype Pollution vulnerability to add our own whitelist and allow XSS. In the end, we can trigger Reflected XSS by the victim just clicking on a link with our payload.