Parsing HTML to remove unsafe elements sounds great, until you look at the HTML specification. Its absurd complexity makes this a daunting task, which is exploited in a field called Mutation XSS. This post will explain the general idea of Mutation XSS, what tricks exist, and how to find bypasses. It also contains two examples of a CVE I found in the lxml_html_clean library and a hard challenge combining and showcasing two new tricks.
What is Mutation XSS?
Most Cross-Site Scripting (XSS) vulnerabilities are simply due to forgetting to HTML-escape a field that should contain no HTML at all. These rarely have a filter and are easy to exploit. In some cases, fields should allow some HTML but not dangerous HTML that may execute JavaScript. This often happens in rich text editors that allow you to write clickable links, in bold, italic, and much more formatting. Usually, this formatting is done on the client-side as HTML and is then sent to the server to save.
Of course, the server cannot trust that the client-side didn't alter the HTML content to contain <script> tags, so some sanitization needs to happen to only allow what the regular text editor may generate, like <a> or <strong>. This task is tricky.
In short, Mutation XSS is abusing the parser. Through complex rules such as namespaces, parsing modes, and fixing invalid tag combinations, sanitizers can be confused into parsing the string differently than the browser would. One part that the sanitizer may see as a benign attribute, style content, or other text, the browser in a different context will see as malicious HTML to execute.
Let's start with a quick example. Mutation XSS always relies on differences between the sanitizer's parser and the browser's. The sanitizer often takes these steps:
- Parse the input as HTML
- Traverse the DOM tree and remove any unsafe elements/attributes you encounter
- Serialize the tree back into an HTML string
One situation where the sanitizer's parser differs from the browser's parser is when the context in which the HTML is placed is different. Some tags have special parsing rules that the sanitizer may not be prepared for.
The <title> tag, for example, doesn't contain HTML but Text instead. Any tags inside like <p> are not seen as tags, it only searches for a closing </title> tag before switching back to parsing like regular HTML. This means it can even find this closing tag inside an attribute, like so:
This whole string is parsed as a title tag containing <p id=" as text, then an <img> tag, followed by "> as text. You can see that the syntax highlighter does not even recognize the closing title tag and wrongly sees it as a whole attribute. Crucially, a sanitizer may see the same, especially when it isn't given the context of the <title> tag, only the <p id="</title>..."> string. The sanitizer doesn't know of any starting title tag, so the attribute really is an attribute and it is returned as-is. When this "safe" HTML is then put in between two title tags as we saw above, it suddenly becomes unsafe!
Bugs and Features
It is not always the context that makes a sanitizer differ from the browser, it may also just be a bug in the sanitizer's parser. Imagine if it mistakingly parsed all <title> content as HTML instead of plain text, then the same payload as above would look like a benign <p> tag with a bit of an unorthodox attribute, but no unsafe tags to see here so it is returned as-is again.
Some parsers also intentionally parse an HTML string differently than a browser would, and for that reason are not perfectly suitable for a sanitizer to use. The default DOMParser API, for example, has scripting disabled while parsing. What does this mean? Well, the <noscript> tag has a special effect in this case.
The output of this tool shows what DOMParser sees, just a <p> with some attribute, seems safe so it is returned as-is. But if you load this same HTML in your browser, it triggers the alert()! How does this happen? It comes down to the fact that <noscript> content is parsed as HTML if scripting is disabled, and it is parsed as text (just like the title tag) when scripting is enabled. The DOMParser API has scripting disabled, but almost every browser nowadays has scripting (JavaScript) enabled. In the browser, this causes the content to be parsed as text and it will look for the first closing </noscript> string, even if it looks like an attribute value to us and the sanitizer.
Changing the output
HTML parsing is very sensitive to changes. One tiny change in context can make all the difference in an XSS or not. This is probably the most common form of Mutation XSS where the developer thinks they can safely change something about the safe output from the sanitizer before placing it into the DOM. With carefully crafted input, a change that may be subtle can have severe consequences on how the string is parsed afterward.
Imagine an application that does some filtering of template syntax like {{...}} after sanitizing, with the following code:
html = ;
html = ;
Crucially, the .* inside this pattern may include < or " characters that define the context, which may change with a clever payload. This allows us to once again make the browser interpret an otherwise safe attribute as HTML:
{{
Any sanitizer will see this as a {{ piece of text, then a <p> tag with a large attribute value. But with {{.*?}} removed, it becomes a working XSS payload:
">
Apart from HTML contexts like "in tags", "in text" or "in attributes", there are more specific contexts for tags called namespaces. There are 3 different namespaces in HTML: HTML, SVG, and MathML. An HTML string can temporarily switch to any of these, through <svg> or <math> tags.
In Dom-Explorer, the namespace on the right of an HTML tag has a blue (HTML), green (SVG), or yellow (MathML) background.
Importantly, these namespaces have different parsing rules again that we can abuse. Especially the text-parsing tags in HTML like <style> which aren't recognized in SVG or MathML, so they would be treated as any other tag and their contents would be parsed as HTML. The browser, however, will parse the content as text (CSS in case of style).
An example would be when namespace-changing tags are altered after sanitization, like a British spell checker changing "math" to "maths". An opening <math> tag would not be recognized anymore by the browser and it would stay in HTML. Now, tags like <style> will be read as CSS, but because this tag is not supported in MathML, the sanitizer would read it as more MathML content. This difference allows you to write a comment (<!-- ... -->) that the sanitizer (in MathML) doesn't see as dangerous, but when altered and parsed by the browser (in CSS), a closing </style> tag can be found in what was previously seen as comment content, allowing a malicious <img> tag to be opened right after:
Apart from changing the <svg> or <math> tags themselves, there are more special tags once inside a different namespace to temporarily get out of one. SVG, for example, has <foreignObject> and some others, while MathML has tags like <mtext> to switch back to HTML. You can see an example below (notice the background colors for namespaces):
If any of these tags are obstructed after being sanitized, it can just as well create an exploitable namespace difference.
Not changing the output
One last interesting fact is that HTML may be parsed differently after doing so more than once. Parsing HTML once, serializing it, and parsing again won't guarantee you receive the same parsed content as before! This fact of the specification causes all sorts of issues even with a perfect parser and sanitizer.
I talk about this more in the Unintended Solution section.
It's starting to sound pretty hard to make a safe HTML sanitizer huh?
Methodology
To summarize, we need two things for a Mutation XSS. First is a way to output arbitrary text that isn't sanitized, often in some restricted context that doesn't immediately cause XSS. The output should include <img src onerror=alert()> somewhere, which may be:
- In an attribute:
<a id="<img src onerror=alert()>">- Could be HTML-encoded by some serializers, even the Browser is actively switching to this (ref)
- Raw text elements:
<style><img src onerror=alert()>- Parsed as CSS instead of HTML, so often is not HTML-encoded
- Per the spec, the following elements should have this property as well:
script,xmp,iframe,noembed,noframes,plaintext,noscript(ref)
- Escapable raw text elements:
<title><img src onerror=alert()>- Should be HTML-encoded normally making it unexploitable, but may be a bug
- Per the spec, the
<textarea>element should have this property as well
- Comments:
<!-- <img src onerror=alert()> --> - CDATA:
<svg><!CDATA[[<img src onerror=alert()>]]>- Should be HTML-encoded by the spec, but may be a bug
- Also works in
<math>, can be cleverly combined with namespace confusion
Secondly, we need a way to make the above injected <img> tags to be interpreted as real HTML. This is done through the confusions talked about earlier, like:
- Bugs in the parser
- Features in the parser that make it parse differently compared to the browser
- Altering the output after parsing
- Reparsing
CVE-2024-52595: lxml_html_clean bypass
During a recent pentest, a client was using the lxml_html_clean library to sanitize some HTML before saving it in the database. This library was split off some time ago from the main lxml repository in use by many more projects. It is easy to find all projects using this library on GitHub by searching for the import statement: lxml.html.clean, this shows around 2.2k results at the time of writing.
Because I hadn't seen this sanitizer before, I started looking at its security to potentially find a bypass. As we learned, the parser is crucial to the security of the sanitizer, because it may simply not see some malicious HTML that is interpreted differently by the browser. Therefore the first thing I look at in sanitizers is the parser used, which in this case is the popular lxml library with its .html imports (source). This is a pretty well-known library used often to parse XML, so I did not expect to find big parser issues in there.
At the same time, I noticed that the sanitizer itself is only a single file that is not too large to read in its entirety, so I started reading the source code and following a debugger of some input being sanitized by it. While the most obvious tags like <script> and attributes starting with on were quickly removed, it appeared that style tags were handled in a pretty strange way. (source)
continue
= or
=
# The imported CSS can do anything; we just can't allow:
=
# Something tricky is going on...
=
=
For some reason CSS is being restricted using the _replace_css_javascript(), _replace_css_import(), and _has_sneaky_javascript() functions. While the replace rules are simple regexes, the _has_sneaky_javascript() function is more complicated and first normalizes the content before checking for a few dangerous pieces of syntax:
= .
= .
= .
= .
= .
=
=
=
=
return True
return True
return True
return True
return True
return False
Then I remembered, in Internet Explorer 7 and older, there was a function in CSS named expression() that would evaluate its contents as JavaScript. Obviously, this was a danger for XSS, so this library had to sanitize it, but nowadays Internet Explorer is so old that many sanitizers don't even bother protecting against this attack vector.
This got me thinking, would it be possible to bypass the check for expression() and at least get a bypass for this old IE7 version? The code replaces expression\s*\(.*?\) first, then @\s*import with empty strings, which should already block the function call. But a clever attacker could write something like this to bypass the two replacements if _has_sneaky_javascript() didn't exist:
@))
The search for expression doesn't match, then the @import search does, replacing it with nothing leading to a result of expression(alert(origin)). But the developer of this sanitizer likely knew about this risk and added a second step to check if the result of this replacement contains the expression( string again, which our payload would, completely deleting the whole style content.
Before checking the second time, it normalizes the style by performing 4 steps:
- Remove comments (
/*...*/) - Remove backslashes (
\) - Remove whitespace
- Lowercase the string
Only after these steps is the content checked, returning either True (meaning dangerous, so delete all content) or False (meaning safe, keep original content). Interesting to me was the fact that the normalized content is checked and if it seems safe, the content before normalization is used. Could some important information get lost during the normalization?
Bypass CSS expression() check in IE7
The answer is yes! If we look at the strings it checks, like expression(, the 'Remove comments' step could contain this syntax and not be found anymore if it is put inside a comment.
# <div><style>/* expression(alert(origin)) */</style></div>
But of course, the expression won't be evaluated if it is put into a comment. We must have our payload between /* and */ to hide it from the sanitizer, but still be parsed in CSS. Luckily we can put this comment syntax into a string with quotes for it not to be recognized by the CSS parser anymore!
The cleaner will see the content of this style tag, and remove the @import statement leaving expression(...). The second check in _has_sneaky_javascript() checks all content except for that in between /*...*/, missing the payload. Then the original content is returned forming a working XSS on IE7 that bypasses the cleaner.
Full bypass using namespaces
While fun, the previous bypass was a bit lame in the fact that almost no user today will be vulnerable, because Internet Explorer 7 was already superseded in 2009. I wanted to find a bypass for modern browsers which would likely involve Mutation XSS.
We need to evaluate how good this parser is with a few tests. Because there is no beautiful Dom-Explorer node for the lxml.html parser, I made the next best thing in a simple Python script:
"""Recursive function to print elements in a tree-like structure."""
=
The output shows that it correctly parses nested tags as expected, also setting "<a>" as the content of the <style> tag.
div (text: '\n ')
div class='inner'
style (text: '<a>')
We can easily test if it supports namespaces by putting a <style> tag into <svg> or <math>. The tag should then be seen as any other tag, and allow children because SVG and MathML don't support it.
svg
style (text: '<a>\n')
Interesting! Even though the <style> tag is inside an SVG, it still gets parsed as CSS and output literally. That means it won't sanitize any tags we put into here, but the browser will read them inside the SVG. A payload like the following should work:
Unfortunately, this doesn't quite work and turns into:
This is because of another check inside _has_sneaky_javascript() that checks if the content "looks like tag content" with the following regex:
</?[a-zA-Z]+|\son[a-zA-Z]+\s*=
This regex matches the <img> tag we put into the content to try and output it literally. When this matches, the whole style content is replaced with /* deleted */. Luckily in the previous section, we found a way to bypass this exact function by abusing the /*...*/ normalization. Anything between these comments is ignored by the check, and because we are writing HTML, it does not matter that our input is in a CSS comment as it is not parsing CSS. Therefore, our final payload can become:
The sanitizer thinks the <style> tag starts CSS, it skips all content between /* and */ and outputs it all like so:
Because it is nested inside <svg>, the <style> tag will be seen as any other tag and continue parsing as HTML, until it encounters another malicious <img> tag that it executes with JavaScript, causing XSS and a full bypass of the sanitizer on default settings!
Because MathML also doesn't support style tags, the same payload in that context works too:
Apart from namespace confusion, I later also found that <noscript> tags were interpreted wrongly. Just like DOMParser with scripts disabled, it parses its content as HTML, while the browser reads it as text. This allows us to write a style tag again that will be interpreted as CSS by the sanitizer, but will be ignored by the browser:
The problem comes down to the fact that lxml.html does not support different namespaces like SVG or MathML, which I can't blame them for because it is very tricky to implement perfectly. Instead, it parses everything as HTML which the cleaner just has to deal with. This issue was assigned CVE-2024-52595 after reporting it and an advisory can be read here together with the fix:
https://github.com/fedora-python/lxml_html_clean/security/advisories/GHSA-5jfw-gq64-q45f
My Challenge
While reading some awesome posts from the security community about Mutation XSS, I kept experimenting with the tricks myself. Through reading sanitizer bypasses and weird HTML features, I started to understand the concept pretty well and could find my own vectors using awesome tools like Dom-Explorer.
While doing so, I eventually found an interesting idea that I thought would be worth sharing, but would also be fun as a challenge. During the development of the challenge, I stumbled upon an open issue on JSDOM which sounded interesting and was a perfect addition to the challenge.
Over on Twitter and Bluesky, I posted the following source code:
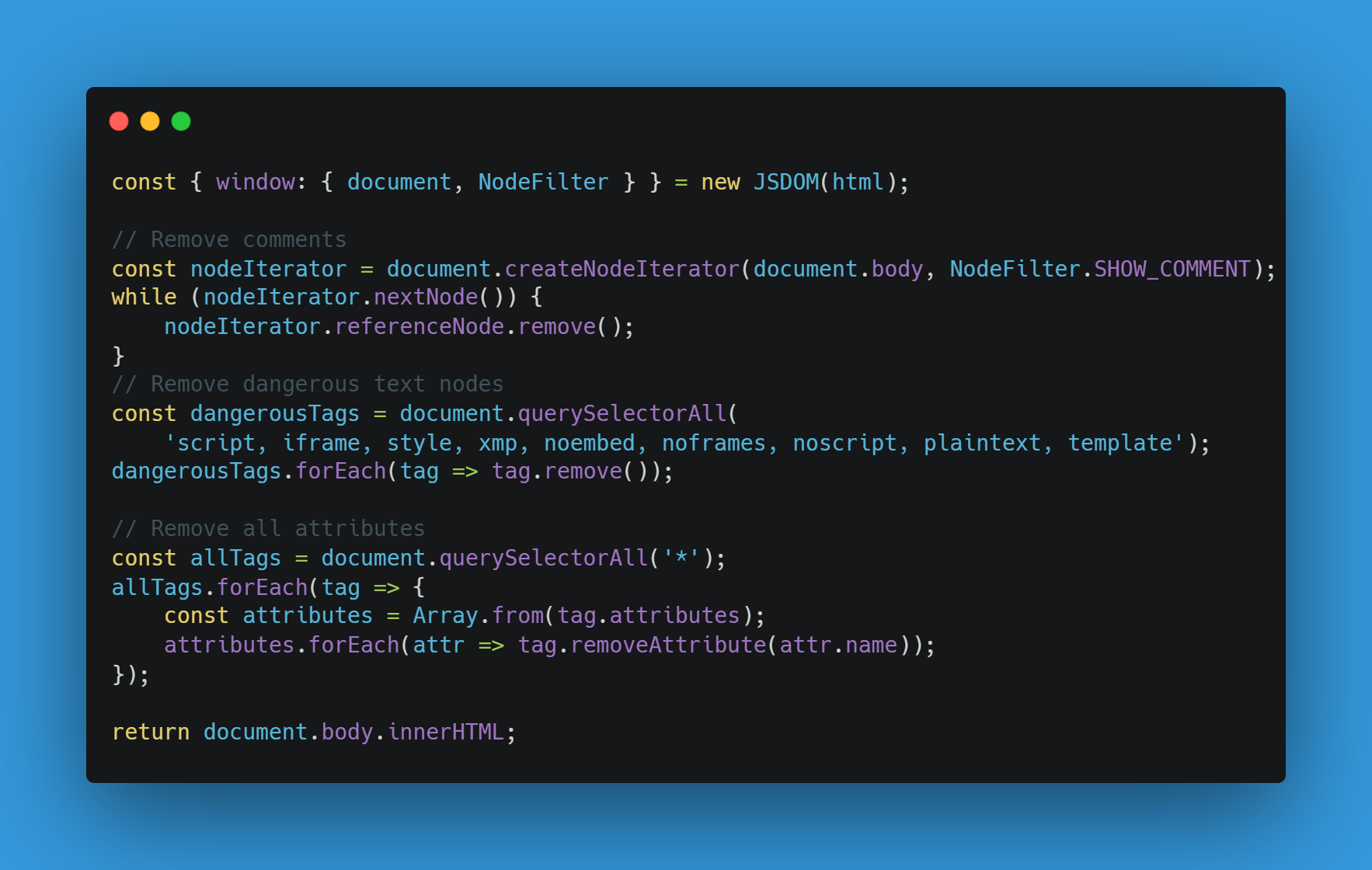
Link: https://gist.github.com/JorianWoltjer/fe0df725a99f6957a0041dabe9dd3fef
The code uses a well-known and up-to-date parser, only removing some dangerous tags and all attributes. Somehow this filter can be bypassed to achieve Cross-Site Scripting.
Solution
We will slowly build out to the final solution, starting with the initial trick I came up with to inspire this challenge. While reading "Idiosyncrasies of the HTML parser" by Simon Pieters, I saw following point:
- HTML (or nested SVG/MathML) can be used in SVG and MathML at certain integration points:
- SVG
foreignObject,desc,title.- MathML
mi,mo,mn,ms,mtext,annotation-xml(if it hasencoding="text/html"orencoding="application/xhtml+xml").
Especially the last one, annotation-xml with a special encoding= attribute seemed interesting to me. It was the first time I saw the presence of an attribute affecting parsing. One operation many sanitizers perform after parsing is removing disallowed attributes. This could create a difference in how the sanitizer saw the content (HTML), and how the browser does (still MathML). Could this be exploited?
Yes! Using tags like <style> that are parsed as text in HTML, but as XML in SVG, we can hide our malicious <img> tag until the attribute is removed, and the parsing changes:
This trick would already bypass the following sanitizer:
Apart from <style>, a few more tags like it exist that return their content as text without being encoded: iframe, xmp, noembed, noframes, plaintext
Two other tags similarly parse their contents as text, but HTML-encode their contents when serialized: title, textarea
While the above challenge was fun, I wanted to add one more trick to it, so I disallowed the use of these special tags that return their content raw. I thought there must be some other way to abuse it using comments, CDATA, any of the HTML-encoded tags, or something else. We already have a namespace confusion after all.
Somehow we will eventually need to write the string <img src onerror=alert(origin)> in the output somewhere and use a confusion to make it execute in the browser. Without the tags like <style>, the only ways I could imagine would be through attributes (which are completely removed), or comments (which were still allowed under my initial rules).
After trying many things with comments and CDATA, I could not make anything work because it would always serialize to something normalized which didn't help the confusion.
While looking for potential open issues in JSDOM, I stumbled upon "Can't remove the attribute 'is'", which seemed like a weird title, must be a user error I thought. But when more carefully looking at the comments, this does seem like weird behavior:
The result on jsdom@15.x.x
vvvThe result on jsdom@16~18
vvv
As explained in the reply, this was an intentional change to jsdom to align with web standards.
jsdom 16.2.0 added (proper) support for custom elements, and according to the latest web standards, the
is=attribute cannot be removed after element creation.
After testing it, I could confirm that indeed the is= attribute is kept!
// <div></div>
// <div is="set with is"></div>
// <div is="<img src onerror=alert(origin)>"></div>
This allows us to get a normally disallowed payload into the output, all that's left is abusing the confusion to make it be read as a real tag. We can start to theorize how this may happen with two different namespaces. Using the <title> or <textarea> tag we can make HTML switch to a text parser, but the same tag in SVG would just continue parsing as XML. Take the following example:
So the above example is safe in SVG, and dangerous in HTML. With the <annotation-xml> trick described earlier, we can make the sanitizer parse HTML, and the browser parse MathML. These don't exactly align yet. We will have to dance around the namespaces to make them split as we want them to be.
If we can somehow switch the sanitizer to SVG while switching the browser to HTML, we can exploit it with the trick above. Luckily, there are more "integration points" that switch from one namespace to another. One you already know is <svg>, in HTML, it switches the namespace to SVG. If we would use this, the sanitizer would go from HTML to SVG while the browser would stay in MathML because <svg> is not special in that context.
Note: for some reason the
<x>before<svg>is required, otherwise it is seen as a real SVG tag by MathML
That's one requirement down, one more to go, just switch the browser in MathML to HTML while keeping the sanitizer in SVG. But what difference is there between these two namespaces? Well, there are tags like <mtext> in MathML that switch to HTML, but aren't special in SVG. This is the last piece of the puzzle, because now our sanitizer is in the SVG namespace (safe) while the browser is in the HTML namespace (dangerous).
We will add the <textarea><a is="</textarea>..."> payload to the end of this to exploit the confusion and inject a malicious <img> tag:
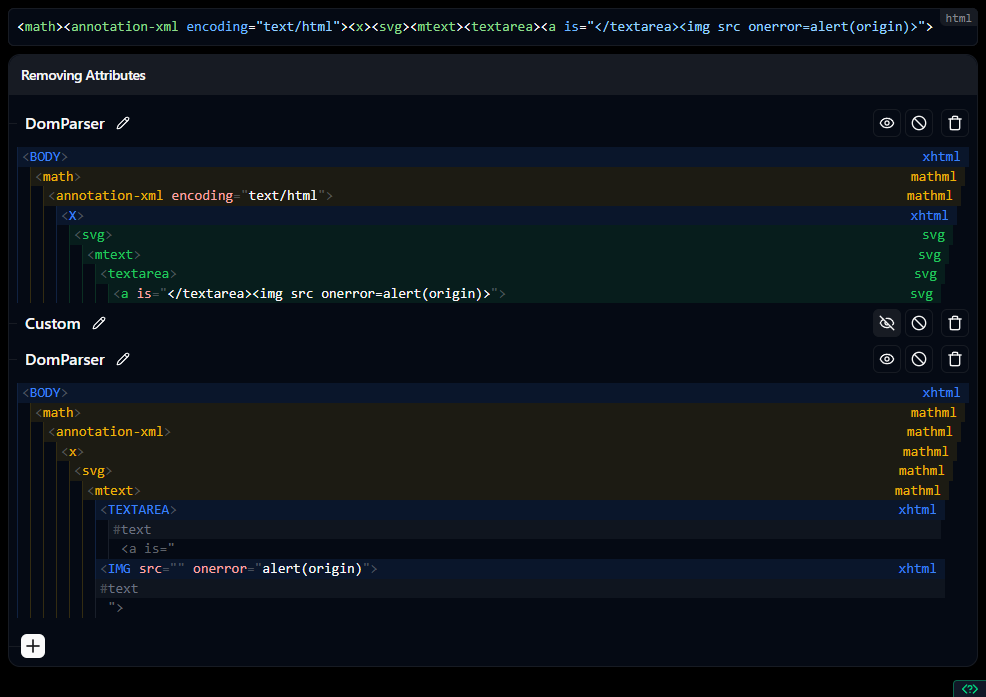
Here is an interactive link, above is a screenshot for future proofing.
This is the final payload that bypasses the sanitizer. We can test it by putting it through the original challenge's source code:
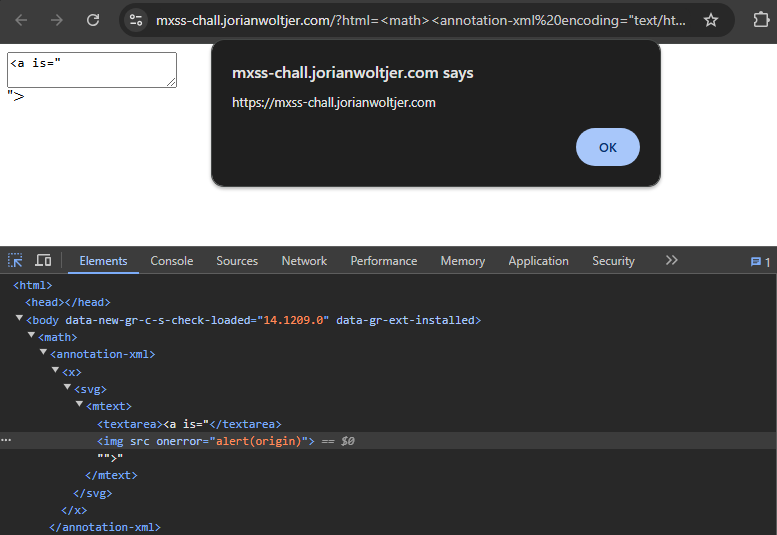
// <math><annotation-xml><x><svg><mtext><textarea><a is="</textarea><img src onerror=alert(origin)>">
// </a></textarea></mtext></svg></x></annotation-xml></math>
When rendered in the browser, it successfully triggers the XSS:
Unintended Solution
To avoid unintended solutions, I limited the length of the input to 1000 bytes, which should prevent the deeply nested payloads that have been haunting DOMPurify for the last few months (read more). Also removing comments, because while I couldn't make anything work, I expected it may still be possible to abuse.
Unfortunately for me, this still wasn't enough because @zakaria_ounissi found an unintended solution just a day after I posted the challenge. While they abused the same is= attribute trick, their way of confusing the namespaces was different and more traditional. The following was their payload:
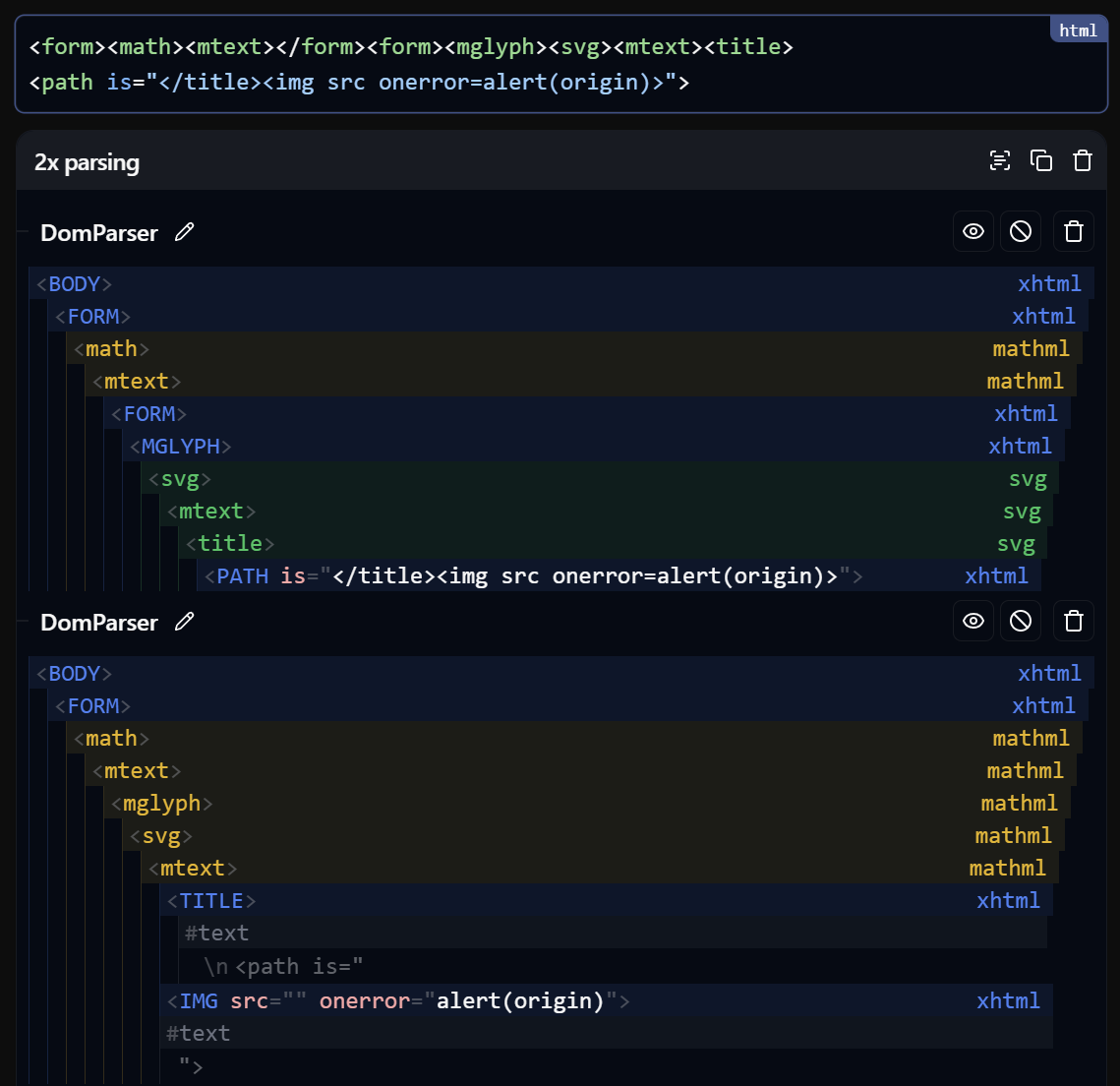
Here is another an interactive link, above is a screenshot for future proofing.
This payload abuses an interesting fact of HTML that the output of serializing and deserializing (parsing) may differ from the input. This is very unintuitive because: imagine you have some data that you serialize as JSON, and then parse again back to an object. It would be crazy if the object is suddenly different from what you put in. This is exactly what happens with HTML.
The following is the real meat of the payload:
The nested <form> tags with MathML in-between cause the first serializer to output two nested <form> tags, which should normally be impossible. Therefore, the next round of parsing sees that the inner form is not allowed while already in a form, and ignores it. The <mglyph> tag seems to only be seen as MathML when it is a direct descendant of the <mtext> tag.
This causes the first round of parsing (in the sanitizer) to see a form in between <mtext> and <mglyph>, not recognize it as MathML, and instead choose for regular HTML.
After serializing and reparsing (in the browser), the form is gone and the <mglyph> is suddenly recognized as MathML, creating a namespace confusion.
They abuse it exactly as I did in the intended solution, by opening an <svg> tag which switches HTML to SVG, but leaves MathML alone. Then <mtext> to switch MathML to HTML, and leave SVG alone. Now the sanitizer is in the SVG namespace, while the browser is in the HTML namespace.
Finally, this allows them to open a tag that is special in HTML (like <title>) and seen as any other tag in SVG. The content of this will be parsed as more SVG content (XML) by the sanitizer, while the browser in HTML is looking for a closing </title> string. They put it in the is= attribute just like in my intended solution to ensure it is kept, and because the browser is parsing text instead of HTML, it recognizes the closing tag and opens the malicious <img>.
For this double-parsing unintended solution, I later released a patched version that went unsolved to the making of this post.
Conclusion
Mutation is a fascinating concept with seemingly infinite depth (pun intended). Equipped with these techniques, even the "good" sanitizers may fall because they trust their parser too much. I hope you found this whole adventure just as interesting as I did and that you learned something new. Now, go hack some sanitizers!